Cloud Cost Optimization & FinOps: Strategic Architecture for 2026
The Macroeconomic Imperative of FinOps and the “Cloud+” Evolution

The global cloud computing market, encompassing Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS), was valued at approximately $943 billion in 2025 and is projected to definitively surpass the $1 trillion threshold in 2026. This exponential growth is driven primarily by enterprise modernization, complex multicloud architectures, and the pervasive integration of accelerated computing for artificial intelligence workloads. However, this rapid scaling has exposed a critical inefficiency within modern technology operations: industry data consistently indicates that between 27% and 35% of all enterprise cloud expenditure is entirely wasted due to rampant overprovisioning, orphaned infrastructure, and insufficient financial governance.
The discipline of Cloud Financial Management, universally adopted under the moniker of FinOps, is undergoing a profound structural recalibration to address this crisis. The FinOps Foundation’s State of FinOps 2025 report reveals a stark shift in practitioner priorities. For previous generations of cloud engineering, the primary objective was simply achieving visibility through tagging taxonomies. In 2025 and moving into 2026, “Workload Optimization and Waste Reduction” has become the paramount priority for 50% of surveyed organizations, outpacing cost allocation and forecasting by a clear margin. This metric indicates a mature market that has achieved baseline visibility and is now aggressively pursuing the reclamation of wasted capital.
Furthermore, the operational bottlenecks within FinOps are transitioning. Historically, the primary barrier to FinOps success was a lack of executive alignment. The 2025 data indicates that organizational alignment concerns have decreased by 9%, suggesting that corporate leadership now fundamentally understands the existential necessity of cloud cost controls. Consequently, the friction has shifted to operational resourcing. Investment in FinOps tooling and automation increased by 20% year-over-year, highlighting a market-wide recognition that manual, ticket-based optimization workflows are structurally unscalable and largely ignored by feature-driven engineering teams.
The most disruptive vector across the current FinOps ecosystem is the management of Artificial Intelligence expenditure. Approximately 63% of FinOps teams are now responsible for managing AI costs, representing a 100% year-over-year increase. Because AI inference costs are highly elastic, rely heavily on GPU instances, and often circumvent traditional compute tagging structures, optimization activities for AI are currently viewed as a secondary, future concern. Instead, organizations are heavily focused on the foundational FinOps domains of “Understand Cloud Usage and Cost” and “Quantify Business Value” to simply track AI API calls and infrastructure utilization before attempting algorithmic right-sizing.
To accommodate this paradigm shift, the FinOps Framework was officially updated in March 2025 to embrace a “Cloud+” approach. This updated nomenclature formally acknowledges that modern technology spend is no longer confined solely to public IaaS environments. The integration of SaaS application costs, private cloud infrastructure, and AI-specific deployments into a single, unified financial data model is now a core requirement for any mature FinOps practice.
SaaS Unit Economics: Marginal Cost and the Anatomy of Gross Margins
For early-stage and growth-phase Software-as-a-Service organizations, total cloud expenditure is merely a secondary metric; the primary metric that dictates survival is the marginal cost of delivery. Marginal cost represents the exact financial expenditure required by the underlying architecture to serve one additional customer or process one additional transaction. This metric serves as the ultimate bridge between technical architecture and enterprise profitability. If the cost of multi-tenant database queries, network egress, and background processing scales linearly or exponentially with user acquisition, the business model is structurally unsustainable, regardless of topline revenue growth or market share capture.
Understanding the direct correlation between cloud infrastructure efficiency and SaaS Gross Margins is critical for Chief Financial Officers (CFOs) and venture capital investors. Gross margins directly dictate a company’s valuation multiplier, investor attractiveness, and its ability to internally fund product development, sales, and marketing. A SaaS organization operating at an 85% gross margin is generally considered highly efficient, demonstrating a highly repeatable business model with immense profit potential baked into its core offering. Conversely, a gross margin hovering around 55% raises significant investor concerns, indicating that bloated infrastructure costs are eroding potential capital and creating a margin leak that threatens the sustainability of the enterprise.
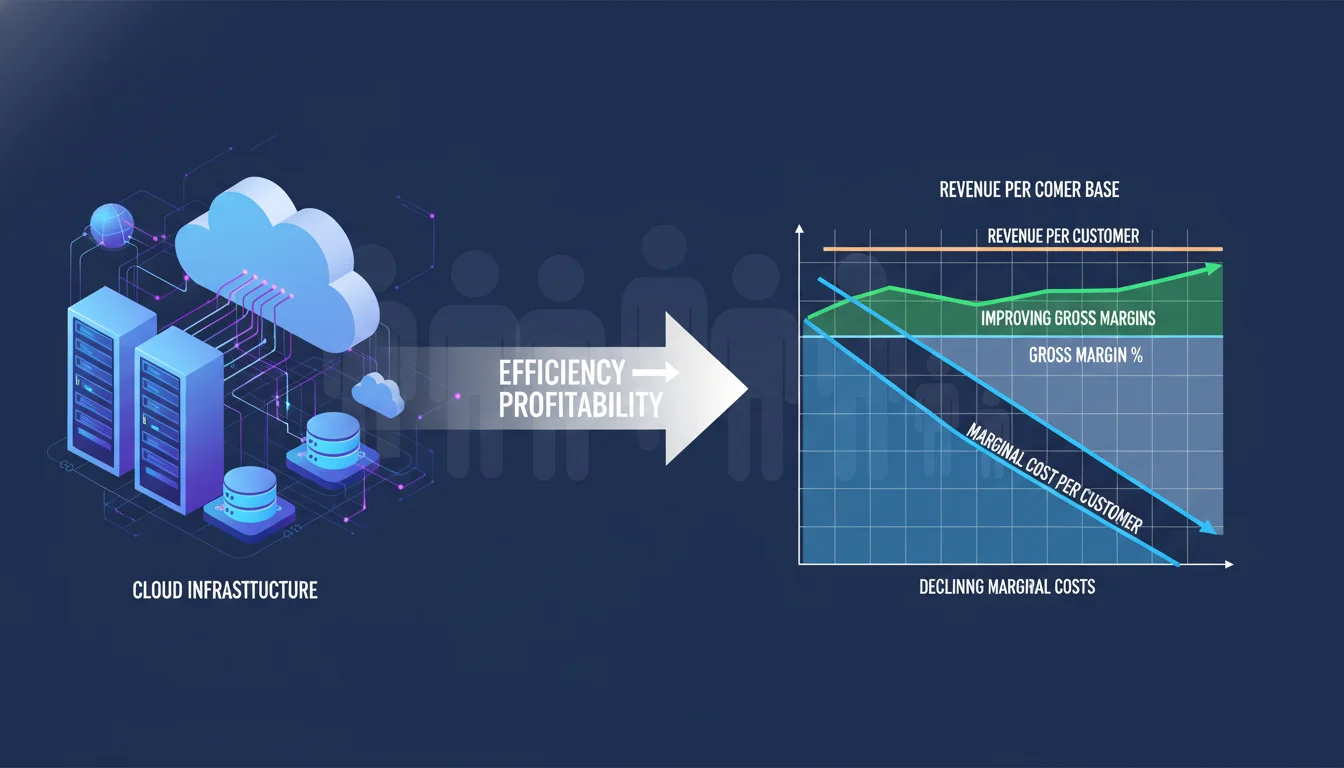
A significant challenge in accurately tracking SaaS margins is distinguishing between direct and indirect costs. Direct costs can be easily attributed to a specific customer—for instance, a dedicated single-tenant database. Indirect costs, however, involve shared databases, sprawling Kubernetes clusters, and overarching networking infrastructure that cannot be cleanly tagged to a single user. Traditional cost management tools that rely strictly on native public cloud tagging fail spectacularly in multi-tenant environments because they cannot parse the granular telemetry required to allocate shared compute.
Without unit economics, unexpected engineering events can devastate margins silently. In a documented case study, a startup’s application developed a memory leak that caused CPU spikes every few hours. The automated scaling group responded by launching over 450 new instances over 30 days. Because the instances were billed for full hours despite having 10-minute lifespans, the company incurred $18,400 in monthly waste for computing power that solved nothing. Basic visibility tools would identify an Elastic Compute Cloud (EC2) spike, but proper unit economics tooling would immediately flag that the “cost per transaction” had drastically and illogically deviated from the historical baseline, prompting immediate engineering intervention.
Crucial SaaS Financial Metric
Definition and Architectural Relevance
-
Marginal Cost
The incremental infrastructure cost incurred by adding one additional user or processing one more transaction; dictates true scalability.
-
Gross Margin
The percentage of revenue retained after subtracting the Cost of Goods Sold (COGS). Highly correlated with venture valuation multipliers.
-
Cost of Goods Sold (COGS)
The direct costs of operating the subscription service, heavily comprised of public cloud computing and SaaS licensing fees.
-
Revenue Churn
The amount of revenue lost over a period compared to the previous period. High infrastructure costs can force price increases, driving churn.
Native AWS Cost Optimization: The Era of Agentic Automation
Amazon Web Services (AWS), retaining its position as the dominant global public cloud provider, has aggressively expanded its native Cloud Financial Management (CFM) suite to address the demands of the 2026 landscape. The announcements from AWS re:Invent 2025 and FinOps X 2025 signify a strategic pivot toward embedding cost optimization directly into the fabric of infrastructure operations, utilizing artificial intelligence to minimize the need for manual engineering intervention.
Compute Optimizer Automation and Resource Remediation
Historically, AWS Compute Optimizer provided highly detailed recommendations for right-sizing EC2 instances, Elastic Block Store (EBS) volumes, and Lambda functions based on historical utilization patterns. However, executing these recommendations required manual engineering effort, which often resulted in optimization tickets languishing in backlogs. The introduction of Compute Optimizer Automation fundamentally alters this dynamic by allowing organizations to turn recommendations into automated savings.
This automation capability permits the automatic implementation of EBS volume optimizations, including the automated snapshotting and subsequent deletion of unattached volumes, as well as the seamless upgrading of older generation volumes to newer, more cost-efficient architectures.
Organizations can now schedule these infrastructure operations on a recurring or one-off basis, apply rule sets to multiple recommendations simultaneously, and algorithmically track the estimated savings generated by the automated actions. This represents a crucial evolutionary step toward “self-healing” infrastructure from a purely financial perspective.
Advanced Artificial Intelligence in Cloud Financial Management
The injection of AI into AWS billing tools is actively bridging the traditional gap between finance professionals and software engineers. The release of the Billing and Cost Management MCP Server enables developers to interact with AWS cost data, analyze trends, and generate estimations directly within their Integrated Development Environment (IDE) or Command Line Interface using natural language queries. Furthermore, Amazon Q Developer has been deeply augmented to conduct complex cost investigations, analyze billing anomalies, and perform custom calculations through conversational interfaces. By surfacing financial data directly into the developer’s native workflow, AWS is significantly reducing the friction associated with “shifting left” on cost accountability.
AWS has also substantially enhanced its Machine Learning-Powered Cost Forecasting.
The predictive horizon has been extended from 12 months to 18 months, leveraging up to 36 months of historical consumption data. Crucially, this update includes “Explainable AI Insights,” which explicitly details the underlying architectural cost drivers and the statistical confidence levels of the forecast. This moves predictive billing away from opaque algorithms toward transparent, defensible financial modeling. In the realm of architecture, AWS is utilizing AI services for automated Well-Architected reviews, deploying agentic AI to synthesize data from multiple sources to automatically evaluate architectures against best practices for cost optimization.

Native Cost Allocation, Commitment Management, and Waste Identification
Cost allocation remains the foundational bedrock of all showback and chargeback methodologies. Recognizing the inherent complexity of tracking containerized workloads, AWS introduced native Kubernetes Label Support for Split Cost Allocation. This feature allows for the direct importation of Kubernetes namespace and pod-level labels into the AWS Billing engine as Cost Allocation Tags. This enables FinOps teams to attribute Elastic Kubernetes Service (EKS) infrastructure costs down to the individual microservice or application level natively, without relying entirely on third-party data aggregators.
Regarding commitment management, AWS launched Database Savings Plans, offering up to 35% savings across nine different database services with a 1-year commitment and zero upfront payment requirements. This applies to both serverless and provisioned database deployments on newer generation instances, reflecting the growing enterprise need for flexible discount instruments beyond pure compute. Additionally, granular Reserved Instance (RI) and Savings Plans Sharing Preferences allow overarching payer accounts to restrict, prioritize, or isolate how discount instruments float across member accounts, perfectly supporting complex corporate structures and compliance requirements.
Waste reduction requires the immediate and algorithmic identification of orphaned infrastructure. The new NAT Gateway Idle Detection feature specifically distinguishes between a truly unused NAT gateway and one that is intentionally sitting idle for disaster recovery (DR) purposes. This distinction is critical; NAT gateways charge for both hourly uptime and data transfer (ingress/egress), frequently causing unexpected and massive billing anomalies when left unmonitored by architecture teams. Furthermore, AWS has introduced a Cost Efficiency Score, a benchmark metric that evaluates potential savings against total addressable spend, mathematically incorporating right-sizing opportunities, idle resource identification, and commitment coverage into a single executive Key Performance Indicator (KPI).
Further native optimization includes the introduction of replication support and Intelligent-Tiering for Amazon S3 Tables, enabling automatic cost optimization through intelligent storage tiering and simplified table replication across AWS Regions and accounts, alongside Amazon S3 Storage Lens integrating performance metrics for billions of prefixes. To support modern reporting standards, AWS Data Exports now natively supports the FinOps Open Cost and Usage Specification (FOCUS) 1.2 standard, adding new fields for capacity reservation information, invoice IDs for reconciliation, and virtual currency support.
-
AWS Native Feature Launched (2025/2026)
- Compute Optimizer Automation: Primary FinOps Function: Waste Reduction. Architectural Impact: Automatically snapshots/deletes unattached EBS volumes and upgrades generations.
- Kubernetes Split Cost Allocation: Primary FinOps Function: Cost Allocation. Architectural Impact: Ingests EKS pod/namespace labels directly into AWS Billing for microservice tracking.
- NAT Gateway Idle Detection: Primary FinOps Function: Anomaly & Waste. Architectural Impact: Distinguishes between truly idle gateways and active DR infrastructure.
- Database Savings Plans: Primary FinOps Function: Rate Optimization. Architectural Impact: Provides up to 35% discounts across nine database types with a 1-year commitment.
- Billing & Cost Management MCP: Primary FinOps Function: Engineering Alignment. Architectural Impact: Allows developers to query cost impacts via natural language within their IDE.
Enterprise Governance: AWS Organizations, Service Control Policies, and Identity Architecture
When global enterprises exceed millions of dollars in monthly cloud expenditure, the FinOps operational model shifts from identifying marginal costs to enforcing massive-scale financial governance, cross-charging internal business units across global geographies, and ensuring strict regulatory compliance.
The technical requirements for operating at this scale are rigid and unforgiving. Enterprise FinOps teams must seamlessly integrate with AWS Organizations. Enabling “All Features” mode within AWS Organizations is the foundational key that unlocks the full suite of governance services across the multi-account ecosystem. The most powerful mechanism unlocked by this configuration is the Service Control Policy (SCP). SCPs act as absolute, preventative financial and security guardrails that supersede any localized account permissions.
For example, a global enterprise must strictly adhere to data residency regulations like GDPR, which dictate that European customer data cannot be processed in external geographic regions. Using SCPs, the central FinOps and architecture team can enforce a mathematically absolute policy that denies actions like creating S3 buckets or launching EC2 instances in any AWS region outside of approved European locations. From a purely financial perspective, SCPs can be deployed to deny the launch of hyper-expensive, GPU-heavy instance types unless the deploying account possesses a specific, pre-approved tag, effectively stopping runaway architectural spend before it is ever provisioned. The “All Features” mode also enables centralized, immutable logging through organization-wide AWS CloudTrail trails and allows for consistent compliance monitoring at scale with AWS Config conformance packs.
The Enterprise Identity Gap: Overcoming SSO and RBAC Limitations
A highly complex and often overlooked challenge in enterprise FinOps deployment is the management of digital identities across massive environments. Standard Single Sign-On (SSO) and Role-Based Access Control (RBAC) mechanisms frequently fail to accommodate the complex multi-layer identity architecture required by global conglomerates.
Enterprise Identity Management fundamentally operates on two interconnected layers: Organization-Level Identity (Layer 1), which handles company hierarchies, department structures, multi-tenant boundaries, and cross-organizational access; and User-Level Identity (Layer 2), which handles individual authentication, role assignments, and permission inheritance. The complexity explodes when these layers interact. A single engineer might require localized, unrestricted read-write access to a sandbox account, limited read-only access to a production account, and global financial audit privileges to view cross-charged billing data.
According to industry analysis, 73% of organizations still rely on identity architectures designed for single-domain environments, creating an “Enterprise Identity Gap”. Mature FinOps platforms designed for the enterprise must seamlessly integrate with corporate Identity Providers (IdP) via Security Assertion Markup Language (SAML) and utilize Just-in-Time (JIT) provisioning to map these complex, multi-layered RBAC hierarchies to specific financial dashboards and cost workspaces, ensuring that users only view the financial data relevant to their specific business unit.
FinOps Software for Startups and Growth-Stage SaaS
For SaaS startups, traditional native tools often fail to provide the deep, multi-tenant unit economics required to protect gross margins. These organizations require agile, fast-to-deploy software that translates multi-cloud invoices into engineering context. The following platforms represent the leading solutions for establishing unit economics and engineering accountability within growth-stage environments.
CloudZero: Engineering-First Cost Intelligence
CloudZero is engineered specifically to correlate cloud spend directly with business value, focusing intensely on shifting financial accountability back to the engineering teams that provision the infrastructure. The platform ingests massive amounts of multi-source billing data across AWS, Azure, GCP, and critical PaaS/SaaS providers like Snowflake and Databricks.
A defining architectural advantage of CloudZero is its code-based allocation methodology. It is widely acknowledged across the FinOps discipline that achieving “perfect tagging” across a rapidly iterating, agile startup infrastructure is practically impossible. CloudZero mitigates this failure point by combining application telemetry with machine learning algorithms to logically allocate untagged and shared resources—such as multi-tenant databases and Kubernetes cross-namespace egress traffic—without requiring immaculate tagging hygiene. By integrating directly into developer workflows, CloudZero can definitively correlate a specific pull request (PR) or code deployment with a subsequent spike in the cost-per-request metric.
However, the depth of CloudZero comes with implementation friction. The initial setup is non-trivial, frequently requiring the configuration of thousands of lines of YAML files to establish complex business mapping rules, leading to a steep learning curve and delayed time-to-value. Furthermore, CloudZero’s pricing model is tied to annualized cloud spend percentages.
Market data based on verified purchases indicates that startup deployments with $1M to $2M in annual cloud spend typically pay $10,000 to $15,000 annually (an effective rate of ~1.0%), while enterprise deployments exceeding $10M in spend average $55,000 to $80,000 annually.
Finout: Unified MegaBill and Virtual Tagging Architecture
Finout approaches SaaS cost management through the lens of a unified “MegaBill,” aggregating raw usage and billing data across all major public clouds, Kubernetes clusters, and tertiary SaaS services (e.g., Datadog, Confluent, Oracle) into a single, comprehensive pane of glass. For SaaS startups, Finout excels via its Unit Economics widget, which mathematically calculates precise metrics like cost-per-user and continuously assesses the health of SaaS margins.
Finout solves the shared resource allocation problem through its proprietary AI-powered Virtual Tagging (VTags) system. This system allows FinOps practitioners to instantly overlay a logical business structure onto their cloud bill, cleaning up untagged resources and reallocating shared costs without forcing engineers to alter the underlying infrastructure tags. Once cost drivers are defined in the dashboard, the widget breaks down cloud spend to reveal the exact financial cost required to support each unit, tracking the trend of $/user or $/GB stored over time. This empowers executives to determine if rising costs are due to healthy business growth or underlying code inefficiencies.
Finout differentiates itself structurally through its commercial pricing model. Unlike tools that charge a punitive percentage of overall cloud spend, Finout utilizes a fixed yearly fee locked into broad annual cloud bill tiers (e.g., $1M-$10M, $10M-$25M), providing transparent, predictable pricing that does not penalize a growing company for scaling its infrastructure.
Vantage: Self-Serve Agility and FOCUS Standardization
For early-stage startups requiring immediate multi-cloud visibility without the heavy integration lift associated with CloudZero, Vantage serves as a highly effective, self-serve FinOps platform. Vantage supports over 20 native integrations, seamlessly pulling billing data from AWS, Azure, Google Cloud, Kubernetes, MongoDB Atlas, and importantly, highly variable AI providers like OpenAI and Anthropic.
Vantage is explicitly optimized for rapid deployment and immediate Return on Investment (ROI). While other platforms require months of telemetry integration, Vantage prioritizes out-of-the-box dashboards, rapid anomaly detection, and historical forecasting. Vantage has aggressively embraced the FinOps Open Cost and Usage Specification (FOCUS) framework, launching a free converter site designed to standardize disparate AI and SaaS invoices into the unified FOCUS format. To assist with proactive optimization, Vantage employs an AI-powered “Autopilot” and a Vantage Agent to identify savings opportunities, alongside deep engineering integrations for Terraform, GitHub, and Slack.
The commercial accessibility of Vantage makes it an ideal entry point. The platform offers a completely Free tier for infrastructures under $2,500 in monthly spend, a Pro tier at $30/month for up to $7,500 in spend, and a Business tier at $200/month for up to $20,000 in spend. As companies mature, Vantage provides an Enterprise tier featuring unlimited tracked spend, dedicated account representation, and robust RBAC and SSO integrations.
Platform Comparison
CloudZero:
- Primary FinOps Strength: Deep Unit Economics and Engineering Accountability
- Cost Allocation Methodology: Telemetry and Code-based logic
- Pricing Structure and Target Audience: Custom % of spend ($10K+). Best for engineering-led tech startups.
Finout:
- Primary FinOps Strength: Unified MegaBill across IaaS and SaaS
- Cost Allocation Methodology: AI Virtual Tags (VTags)
- Pricing Structure and Target Audience: Fixed yearly tier. Best for scale-ups needing predictable OPEX.
Vantage:
- Primary FinOps Strength: Self-serve speed, AI costs, and multi-cloud visibility
- Cost Allocation Methodology: Tag-based and FOCUS formatting
- Pricing Structure and Target Audience: Low monthly flat fees. Best for early-stage and agile mid-market.
The Automation Execution Tier: Shifting from Reporting to Remediation
As organizations transition from the startup phase into mid-market maturity (typically $100,000 to $500,000 in monthly cloud spend), the financial leverage shifts dramatically. While unit economics remain vital for product teams, the overarching financial burden becomes heavily dependent on the efficient procurement of cloud provider discounts and the ruthless elimination of physical waste.
The industry is experiencing a widespread realization that traditional reporting dashboards frequently fail to generate actual savings. Tools generate automated insights and prioritized recommendations, but they hand the physical work back to engineers via ticketing systems to validate and apply the fixes. In fast-moving environments, this ticket-based optimization is rarely completed because engineers naturally prioritize shipping revenue-generating code over cleaning up legacy resources. Consequently, knowing who spent the money is no longer synonymous with saving it.
This operational failure has led to the rapid proliferation of autonomous execution platforms. These tools do not merely provide visibility; they algorithmically execute financial instruments and physical infrastructure changes directly against the cloud provider’s APIs, achieving near-perfect optimization coverage with zero human intervention.
ProsperOps: Algorithmic Rate Optimization
ProsperOps operates as a premier autonomous FinOps platform specifically engineered to mathematically maximize the Effective Savings Rate (ESR) on AWS compute environments. Rather than providing static dashboards that suggest manual RI purchases, ProsperOps utilizes advanced machine learning and predictive analytics to continuously monitor actual EC2 usage patterns. It then dynamically blends various discount instruments—including AWS Savings Plans, Reserved Instances, and Committed Use Discounts—in near real-time.
The platform constantly exchanges and modifies these discount instruments to align precisely with shifting infrastructure demands, entirely mitigating the severe financial risk of long-term vendor lock-in on obsolete instance types. By synchronizing commitment management actions with actual workload schedules, ProsperOps targets an ESR of 40% or greater. Crucially, the platform operates entirely hands-free; it requires no architectural alterations, no manual forecasting, and no disruption to engineering workflows. ProsperOps leverages a highly favorable zero-risk pricing model, charging a small percentage only on the net-new savings it actively generates, thereby perfectly aligning the vendor’s financial incentives with the client’s cost reduction goals.
nOps: Comprehensive Commitment and Infrastructure Automation
In direct competition with ProsperOps, nOps offers highly robust commitment management alongside deeper, physical infrastructure execution. nOps differentiates itself by guaranteeing 100% utilization of the RIs and Savings Plans it autonomously manages.
Moving beyond pure financial engineering, nOps automates the physical orchestration of AWS Spot Instances, dynamically moving fault-tolerant workloads to discounted capacity. It also provides automated idle EC2 and EBS cleanup, resource scheduling, and one-click migrations from older GP2 storage volumes to the more cost-efficient GP3 architecture. This automation frees engineering teams from the toil of manual infrastructure rightsizing. Furthermore, nOps offers “nOps Business Contexts” as a free platform feature, making it easy to understand and allocate 100% of AWS costs down to individual container workloads, pairing deep visibility with its premium automation tools.
Zesty: AI-Driven Storage and Compute Auto-Scaling
Zesty focuses intensely on deep, physical automation, trading broad FinOps dashboarding features for highly targeted infrastructure execution. The Zesty Commitment Manager optimizes EC2 discount plans and Relational Database Service (RDS) commitments automatically to ensure maximum coverage with minimal financial risk.
However, Zesty’s most disruptive feature is “Zesty Disk.” This tool leverages machine learning to physically and automatically scale EBS volumes up or down in real-time, perfectly matching the immediate needs of the application. This eliminates the deeply entrenched enterprise practice of massively overprovisioning storage blocks to prevent application downtime, optimizing storage utilization and reducing physical storage costs by up to 70%. For containerized environments, Zesty’s Kompass module handles Kubernetes pod rightsizing, persistent volume autoscaling, and node management.
Autonomous Platform Comparison
ProsperOps:
- Rate Optimization (Discounts): Real-time dynamic blending of SPs/RIs. Targets 40%+ ESR.
- Workload Optimization (Infrastructure): Synchronizes resource schedules with commitment actions.
- Pricing & Guarantees: Savings-share (takes a percentage only of savings generated).
nOps:
- Rate Optimization (Discounts): Automated RI/SP management with 100% utilization guarantee.
- Workload Optimization (Infrastructure): Spot orchestration, GP2 to GP3 migration, idle cleanup.
- Pricing & Guarantees: Savings-share model; offers free visibility platform.
Zesty:
- Rate Optimization (Discounts): EC2 and RDS automatic commitment optimization.
- Workload Optimization (Infrastructure): Zesty Disk auto-scales EBS volumes in real-time (up to 70% savings).
- Pricing & Guarantees: Savings-share model.
Heavyweight Enterprise FinOps Platforms: Scale, Finance, and Governance
When corporate cloud expenditure scales into the multi-millions per month, the FinOps operational model is fundamentally distinct from startup operations.
Enterprise FinOps is less about tracking the marginal cost of a specific software feature and more about enforcing massive-scale financial governance, cross-charging highly disparate internal business units, and managing complex vendor relationships across hybrid-cloud footprints. The platforms that dominate this elite sector—IBM Cloudability and VMware CloudHealth—are specifically architected to map these massive corporate hierarchies.
IBM Cloudability (Apptio): Financial Lineage and Business Mapping
Acquired by Apptio and subsequently integrated into the broader IBM enterprise suite, Cloudability is fundamentally a finance-oriented platform. It is built to digest, normalize, and analyze consolidated cloud bills spanning billions of lines of telemetry data across AWS, Azure, Google Cloud, and Oracle Cloud.
Cloudability’s core architectural strength lies in its Business Mapping Engine. This engine correlates raw cloud spend to highly specific business KPIs, projects, or functions utilizing complex declarative labels and virtual reallocation rules. This functionality facilitates rigorous enterprise chargeback processes—moving beyond the theoretical visibility of “showback” (which merely builds cost awareness) to the actual internal financial billing of business departments, creating distinct financial accountability and incentivizing cost-conscious engineering. The platform provides advanced ARIMA-based predictive analytics for budgeting, alongside KPI scorecards that introduce gamification to drive efficiency across disparate global engineering pods.
Real-world deployments of Cloudability yield highly documented, substantial returns. IBM reports that the tool generally facilitates a 30% reduction in cloud unit costs and enables massive organizations to increase their discount commitment coverage beyond 90%. In a documented enterprise case study, the technology platform Hyland utilized Cloudability’s real-time visibility to identify deep architectural inefficiencies. By adjusting settings based on Cloudability’s insights, Hyland successfully reduced their Amazon RDS expenditure by more than 50%.
Similarly, the platform Sportradar utilized Cloudability to reduce its cost-per-transaction by an astounding 90%, while MoxiWorks achieved a 40% discount on EC2 usage by deploying Cloudability’s savings automation. Furthermore, Apptio’s internal Cloud Center of Excellence (CCoE) utilized their own tooling to manage explosive cloud growth, optimizing unit costs by 30% and launching 77 distinct savings initiatives to bring spiking costs back to a sustainable baseline. For massive organizations, Cloudability integrates cohesively with broader IT Financial Management (ITFM) platforms like IBM Turbonomic, bridging the gap between physical application resource management and corporate financial ledgers via ServiceNow integrations for compliance routing.
VMware CloudHealth (Broadcom): Deep Policy Enforcement and Cloud Ops
CloudHealth, currently operated under the Broadcom/VMware umbrella, approaches FinOps primarily through the lens of IT Operations, security posture, and policy-driven governance. While Cloudability focuses intently on financial ledgers and chargeback, CloudHealth excels at establishing operational rules and compliance constraints.
The platform’s proprietary “FlexOrgs” hierarchical engine allows enterprise architecture teams to accurately mirror deeply complex corporate structures, applying bespoke governance policies and spending controls at various tiers of the organization. CloudHealth excels at identifying idle resources, zombie infrastructure, and severe compliance violations across vast multi-cloud and on-premises data center environments. The platform acts as a centralized operational hub, tracking usage patterns and automating remediation actions across AWS, Azure, GCP, OCI, and Alibaba Cloud.
However, enterprise platforms of this scale require a significant operational investment to maintain. Recent market data from Gartner Peer Insights indicates that users frequently experience UI complexity and navigation friction, alongside significant concerns regarding support availability and sales confusion following the Broadcom acquisition. Customers cite a steep learning curve and a confusing mix of operational metrics. Despite this, for massive organizations operating hybrid environments that require the absolute highest degree of multi-cloud operational governance and security auditing alongside cost tracking, CloudHealth remains a formidable, deeply entrenched platform.
Enterprise Capability Matrix
| IBM Cloudability (Apptio) | VMware CloudHealth (Broadcom) | |
|---|---|---|
| Primary Domain Focus | IT Finance, Chargeback, KPI Gamification. | IT Governance, Security, Cloud Operations. |
| Enterprise Hierarchy Engine | Business Mapping Engine. | FlexOrgs Organizational Hierarchy. |
| Cost Allocation Depth | Advanced logic, pod-level Kubernetes via labels. | Tag-driven, Policy-based enforcement. |
| Target User Persona | Central Finance Teams, FinOps CCoE. | IT Operations, Cloud Architects, MSPs. |
| Documented ROI Examples | Hyland (50% RDS reduction); Sportradar (90% transaction reduction). | Strong mature waste reduction; 72% EC2 waste recovery via best practices. |
Niche, Open-Source, and Kubernetes-Specific Optimization Tools
While generalist FinOps platforms dominate the market, highly specialized architectural deployments require purpose-built tooling. The complexity of Kubernetes, specifically, has spawned an entire sub-industry of cost management.
For environments exclusively or heavily reliant on containerization, CAST AI provides specialized, AI-driven automation. CAST AI acts as a node autopilot, dynamically selecting the most cost-efficient compute instances (including aggressively utilizing Spot and preemptible instances) and scaling workloads based on real-time cluster utilization. However, CAST AI is hyper-focused on Kubernetes; organizations operating traditional virtual machines or tracking extensive SaaS sprawl require a supplementary platform for holistic enterprise visibility. Other tools in this domain include Kubecost, which provides deep visibility into Kubernetes but is limited beyond the K8s ecosystem, and Harness Cloud Cost Management, which embeds cost controls directly inside Continuous Integration/Continuous Deployment (CI/CD) pipelines but is considered architecturally heavy.
For organizations looking to build their own automation, open-source solutions provide a highly customizable alternative. Cloud Custodian, a Cloud Native Computing Foundation (CNCF) Incubating project, supports AWS, Azure, GCP, Kubernetes, and OpenStack. It utilizes a YAML-based Domain-Specific Language (DSL) that allows FinOps engineers to create and enforce governance rules in real-time. For example, Cloud Custodian allows teams to easily schedule cloud “off” hours for non-production environments, enforcing automated cost reduction without requiring expensive third-party licensing. Similarly, Ternary has emerged as a strong multi-cloud platform with specifically deep integration and feature parity for Google Cloud Platform (GCP), an area where many legacy vendors historically struggle.
Real-World Implementation: Failures, Triumphs, and the Cloud Center of Excellence
The theoretical application of FinOps tooling is frequently challenged by the realities of enterprise software engineering. Success depends entirely on the operational mandate granted to the FinOps team or the overarching Cloud Center of Excellence (CCoE).
A CCoE spearheads initiatives to reduce waste by establishing automated policies and fostering cross-functional communication. When properly implemented, a CCoE can turn the industry average of 27% cloud waste into multi-million-dollar savings. In a detailed case study, the consultancy Techieonix partnered with a fast-scaling technology platform to optimize their AWS infrastructure. By building a centralized dashboard, utilizing custom Python and Boto3 automation to flag stale resources without relying on raw billing data, and meticulously mapping infrastructure ownership to business units, the team achieved a $6,000 per month (30%) reduction in cloud costs with absolutely zero performance impact or service downtime. This demonstrates that proactive cleanup, when paired with clear cost ownership, yields immediate, tangible ROI.
Conversely, without a CCoE or autonomous tooling, organizations fall victim to architectural compounding. As noted previously, the “auto-scaling death loop” case study, where a simple memory leak triggered a $18,400 monthly bill for transient instances, perfectly illustrates the danger of pairing elastic cloud architecture with slow, reactive financial reporting.
Vendor Pricing Models and Financial Incentive Alignment
When evaluating third-party platforms, FinOps practitioners must heavily scrutinize the vendor’s commercial pricing model to ensure aligned financial incentives. The software procurement landscape in 2026 is highly fractured across three distinct billing philosophies:
-
Percentage-of-Spend Models
Legacy platforms and certain modern tools (e.g., Cloudability, CloudHealth, Harness, and CloudZero) charge between 0.5% and 3.0% of the client’s total annualized cloud spend. This model creates a highly controversial and perverse incentive structure: the software vendor theoretically benefits financially when the client’s cloud bill increases, fundamentally contradicting the goal of cost reduction.
-
Fixed Annual Licensing
Tools like Finout and Vantage (in its lower tiers) offer flat, tiered pricing. This provides the ultimate predictability for Operational Expenditure (OPEX), allowing companies to deploy more compute and scale their business without simultaneously and artificially inflating their FinOps software overhead.
Savings-Share Models
Autonomous execution tools like ProsperOps, nOps, and Zesty operate on a purely results-based model. The vendor takes a percentage cut (e.g., 5-10%) only of the net-new savings it successfully generates through its automated actions. This model perfectly aligns the vendor’s financial incentives with the client’s objective of absolute cost reduction.
Conclusion: The Strategic Convergence of Code and Capital
The discipline of Cloud Cost Optimization in 2026 has irrevocably shifted from retrospective, spreadsheet-based dashboard analysis to proactive, algorithmic execution. As global enterprise dependency on cloud infrastructure expands toward the $1 trillion mark, the corporate tolerance for capital waste generated by idle resources, orphaned data volumes, and mismanaged discount instruments has entirely vanished. Amazon Web Services is rapidly equipping engineers with agentic AI and native automated remediation tools within their IDEs, bridging the historical divide between rapid infrastructure deployment and strict financial accountability.
For Software-as-a-Service organizations, corporate survival and venture valuation are intrinsically linked to mastering unit economics and understanding marginal costs. FinOps platforms that can accurately parse the exact cost of a specific customer transaction out of complex, multi-tenant Kubernetes telemetry are no longer optional—they are mission-critical infrastructure. For the global enterprise, success hinges on deploying highly sophisticated chargeback mechanisms and enforcing hierarchical, automated financial governance via Service Control Policies at a scale that human operators simply cannot manage manually. Ultimately, the maturation of the FinOps discipline dictates that cloud computing is no longer treated as an infinite, unmetered IT resource, but rather as a highly optimized, dynamically scaled financial supply chain that must be algorithmically governed to ensure sustainable corporate growth.


