Programmatic SEO for Affiliate Sites: Scaling Conversions
Programmatic SEO for Niche Affiliate Sites: Scaling Low-Volume, High-Conversion Web Pages

The Paradigm Shift: From Manual Publishing to Programmatic Architectures
Search engine optimization has historically been an artisanal and highly linear endeavor, characterized by the manual creation of editorial content designed to align with broad search intent. However, as algorithmic complexity has evolved and the sheer volume of search permutations has expanded, a structural divergence has occurred, giving rise to programmatic SEO. Programmatic SEO represents a highly technical, automated approach to creating and optimizing thousands, or even millions, of web pages simultaneously. By bridging extensive, deeply nested datasets with flexible, logic-driven front-end templates, web architects can target vast matrices of long-tail search queries that would be economically unviable and logistically impossible to address through traditional editorial processes.
The fundamental architecture of a programmatic SEO system rests on three indispensable pillars: structured data, page templates, and automated scale. Unstructured or poorly formatted data cannot scale; therefore, deeply nested datasets—such as product inventories, demographic statistics, university outcome reports, or software specifications—act as the raw material for the entire operation. Page templates serve as the mold, engineered to be dynamic and recognizable, ensuring that while the layout remains consistent across the architecture, the populated data points create a uniquely valuable experience for the end user. Finally, scale is the mechanism by which hundreds or thousands of page permutations are deployed simultaneously to capture micro-intents across the search landscape.
For niche affiliate websites, this methodology presents an asymmetrical economic advantage. Traditional publishing models require substantial capital expenditure on writers, editors, and SEO specialists to produce a single piece of content, limiting output to tens or hundreds of pages per year. Programmatic execution fundamentally alters the unit economics of content production, lowering the marginal cost of a newly published page to near zero once the underlying infrastructure, data pipelines, and template logic are established. Large-scale platforms like Yelp, TripAdvisor, and Zapier have long utilized this methodology to dominate search engine results pages (SERPs) by generating highly specific directory and integration pages. Zapier, for instance, generates nearly two million monthly organic visits across roughly 56,000 pages, with 44,000 of those pages specifically targeting software integration queries. Today, this capability has been democratized, allowing independent publishers and niche affiliate marketers to construct expansive, data-driven web properties that capture highly specific, low-volume, high-converting search traffic.
Economic Modeling and the Logic of Low-Volume Conversion
The commercial viability of programmatic SEO in the affiliate sector relies on a counterintuitive premise: aggregate traffic volume is a secondary metric compared to aggregate search intent. Programmatic strategies often target low-volume keywords that receive only a handful of monthly searches. However, because these searches represent the absolute bottom of the conversion funnel, the user intent is overwhelmingly transactional. When deployed across tens of thousands of pages, the aggregate traffic yields an exceptionally high return on investment because the traffic inherently converts at a superior rate.
A primary example of this economic model is demonstrated by the software-as-a-service platform Userpilot. By transitioning a portion of their marketing efforts toward a programmatic strategy, they targeted specific, high-intent keyword frameworks such as “[Competitor] alternatives,” “Best [use case] tools,” and “ vs for [use case]”. While the pages generated through this programmatic strategy accounted for less than one percent of their total site traffic, the economic output was vastly disproportionate to the traffic volume.
| Content Strategy Model | Average Cost Per Post | Conversion Rate Performance | Primary Traffic Focus |
|---|---|---|---|
| Traditional Editorial SEO | $275.09 | Baseline | High Traffic Volume (Top of Funnel) |
| Programmatic SEO (pSEO) | $97.00 | 3x Higher than Baseline | High User Intent (Bottom of Funnel) |

As the data indicates, the programmatic approach reduced the cost per post by nearly 65% while tripling the conversion rate. This shift transforms SEO from a generalized traffic-generation mechanism into a highly targeted conversion engine. In the affiliate space, this principle is equally applicable to high-value niches such as insurance, finance, enterprise software, and home improvement. For instance, in the pet insurance vertical—a market where the average owner spends over $730 annually and total insured pets increased by 12.7% in a single year—programmatic pages targeting long-tail breed-specific queries exhibit conversion rates that rival or exceed expensive short-tail head terms.
| Pet Insurance Keyword Group | Average Cost Per Click (CPC) | Average Conversion Rate |
|---|---|---|
| “pet insurance quotes” | $8.00 – $15.00 | 5% – 10% |
| “best pet insurance” | $6.00 – $12.00 | 3% – 7% |
| “[breed] insurance” | $4.00 – $8.00 | 4% – 8% |
| “dog insurance” | $5.00 – $10.00 | 3% – 6% |
| “cat insurance” | $3.00 – $7.00 | 4% – 7% |
The data confirms that granular, low-volume programmatic targets—such as specific breed insurance or narrow software use cases—allow affiliate marketers to bypass highly competitive, expensive short-tail keywords. By generating thousands of specific landing pages that directly match the user’s micro-intent, the programmatic site captures the user at the exact moment of commercial investigation.
Furthermore, aggressive programmatic strategies can play “offense” by targeting competitor queries directly. ElevenLabs successfully executed a programmatic campaign not merely to rank for its own brand, but to systematically capture searches for competitor branded keywords like “Suno AI,” “Uberduck,” and “15 ai”. By generating comparative teardowns programmatically, they captured high-intent traffic actively searching for alternatives to their rivals.
To effectively monitor the success of these low-volume strategies, operators must advance beyond basic vanity metrics. A sophisticated programmatic architecture requires a mature content analytics framework.
| Analytics Maturity Level | Capability Focus | Core Metrics Tracked | Self-Assessment Diagnostic |
|---|---|---|---|
| Level 1: Vanity Metrics | Tracking baseline visibility | Pageviews, sessions, bounce rate, social shares | Can you connect a specific content piece to a closed deal? |
| Level 2: Channel Analytics | Measuring traffic sources and engagement | Traffic by source, time on page, scroll depth | Do you know which channels drive highest-converting visitors? |
| Level 3: Engagement Analytics | Tracking interaction patterns | Video completion, CTA clicks, section depth | Can you identify which content sections lose attention? |
| Level 4: Outcome Analytics | Connecting content to revenue | Conversion rate by template, pipeline influenced | Can you attribute specific revenue to programmatic page clusters? |
Achieving Level 4 outcome analytics allows niche affiliate managers to identify precisely which programmatic templates (e.g., “Cost of living in [City]” vs. “Safety in [City]”) yield the highest financial return, informing where to allocate future crawl budget and API expenditures.
Data Acquisition, Cleansing, and Pipeline Engineering
The success of a programmatic SEO operation is entirely contingent upon the quality, accuracy, and structural integrity of the underlying database. Search engines increasingly utilize entity recognition, knowledge graphs, and verifiable statements to evaluate content; consequently, populating templates with inaccurate, hallucinatory, or duplicate data will quickly trigger algorithmic demotions. The data pipeline typically begins with acquisition, is followed by rigorous cleansing methodologies, and concludes with architectural structuring.
Data acquisition for affiliate niches often involves aggregating public datasets, scraping competitor configurations, or utilizing established application programming interfaces (APIs). Tools like Octoparse enable visual web scraping without requiring extensive development resources, allowing site builders to compile product attributes, pricing histories, and location coordinates directly into raw spreadsheets. Alternatively, official databases provide massive, structured CSV files that serve as foundational datasets. For example, the U.S. Department of Education’s College Scorecard and the National Center for Education Statistics (NCES) provide datasets containing median earnings, employment rates, and outcomes for bachelor’s degree holders. The U.S. Census Bureau’s American Community Survey (ACS) provides deeply granular data on median earnings by educational attainment, geography, and demographics. Accessing these files via CSV offers significant advantages for multi-state analysis, allowing automated data ingestion processes to bypass the formatting artifacts often found in raw Excel downloads.
Once raw data is acquired, it must undergo extensive cleansing. Raw datasets are rarely production-ready; they contain carriage returns, formatting inconsistencies, null values, and duplicate entries. Implementing a sophisticated data cleaning methodology is mandatory to prevent these errors from propagating across thousands of live web pages.
Data Manipulation and Cleansing
Advanced data manipulation environments like OpenRefine and Python’s Pandas library are standard within the programmatic SEO workflow. OpenRefine is particularly valuable for its algorithmic clustering capabilities, which utilize natural language processing techniques to identify and merge typographical errors and inconsistent representations of identical entities. For example, a scraped dataset might contain “NewYork,” “New York,” and “NY.” OpenRefine’s clustering algorithms allow data engineers to standardize these variations into a single, canonical format.
Furthermore, OpenRefine utilizes the General Refine Expression Language (GREL) for advanced ad-hoc data transformations. Through GREL expressions, engineers can automate the removal of leading and trailing whitespaces, split complex multi-value cells into distinct actionable columns, and execute massive string replacements across millions of rows prior to CMS injection.
For larger, more complex pipelines, Python’s Pandas library offers unparalleled programmatic control over data cleansing. Data scientists and advanced technical SEOs utilize Pandas to define custom tool functions that read CSV-formatted strings directly into operational data frames. Within this environment, operators can drop or impute missing values, normalize structural schemas, handle complex time-series data, and execute high-speed vector operations on multi-gigabyte files. Establishing a robust diagnostic framework to assess data quality—including checking for null percentages, verifying data types, and ensuring uniqueness across primary keys—is a non-negotiable step before pushing data to a live environment.
Advanced Technological Stacks and CMS Infrastructure for 2026
The technological infrastructure required to host, render, and serve thousands of programmatically generated pages has advanced significantly. The modern programmatic SEO tech stack relies heavily on decoupling the database from the presentation layer, allowing for dynamic, real-time updates and seamless scaling.
A central component of this ecosystem is the database itself. While simple projects may rely on Google Sheets due to its accessibility and native formulaic capabilities (such as VLOOKUP, HLOOKUP, and CONCATENATE), sophisticated architectures heavily utilize Airtable. Airtable functions as a robust relational database with a highly intuitive user interface, allowing cross-functional teams to construct interconnected tables that map directly to the hierarchical structure of the website.
For the Content Management System (CMS), architects generally choose between traditional monolithic systems, visual no-code builders, and modern headless static site generators.
Traditional and No-Code Platforms
WordPress remains the dominant monolithic choice due to its ubiquity and the power of integration plugins like WP All Import. WP All Import acts as the standard bridge between a finalized CSV or XML feed and the WordPress MySQL database, allowing developers to map specific spreadsheet columns directly to custom fields created by Advanced Custom Fields (ACF). While this method is battle-tested, it suffers from severe operational bottlenecks at scale. Large datasets can take an exorbitant amount of time to process, the interface lacks native dynamic logic routing without extensive PHP customization, and the system relies entirely on static, pre-written text generation.
Conversely, Webflow has emerged as the premier choice for design-centric affiliate marketers seeking pixel-perfect control. By combining Webflow with Airtable and utilizing middleware synchronization platforms like Whalesync, developers establish a continuous, two-way sync between the database and the live website. When an affiliate link, product price, or data attribute is updated in Airtable, Whalesync automatically pushes the revision to the Webflow CMS in real-time, ensuring the programmatic pages remain accurate and fresh—a critical ranking factor for search engine evaluation.
Headless Frameworks and Static Site Generators
For operations requiring tens of thousands to millions of pages, architects deploy static site generators (SSGs) and headless CMS frameworks. Frameworks such as Hugo, Eleventy (11ty), or NextJS paired with a visual database studio like Directus or Supabase offer blazing-fast page generation. These API-first setups provide development teams with absolute control over data modeling, auto-generated REST/GraphQL APIs, and server-side rendering, bypassing the bloat associated with visual website builders.
Furthermore, visual differentiation has become an increasingly critical algorithmic factor. Search engines actively penalize networks of pages that share identical boilerplate templates containing only minor text variations, classifying them as thin or duplicate content. To combat this visual homogeneity, modern stacks integrate automated image generation APIs. Platforms like Orshot allow developers to design a visual template in a studio environment and generate thousands of unique, context-specific images by passing database parameters directly through a dynamic image URL.
The technical implementation of this dynamic visual generation is highly streamlined. An HTML image tag is embedded within the CMS template, calling the image API endpoint. Appended to this URL are specific query parameters matching the database fields, alongside a required security signature and the designated template ID. When the crawler or user accesses the page, the image is rendered on the fly, dynamically printing the unique localized text, ratings, or prices onto the graphic. For multi-page templates, parameters such as page numbers or specific modification syntax can be utilized. This programmatic image injection guarantees that every single URL possesses unique visual assets, dramatically elevating user engagement metrics, social sharing, and the perceived authority of the domain.
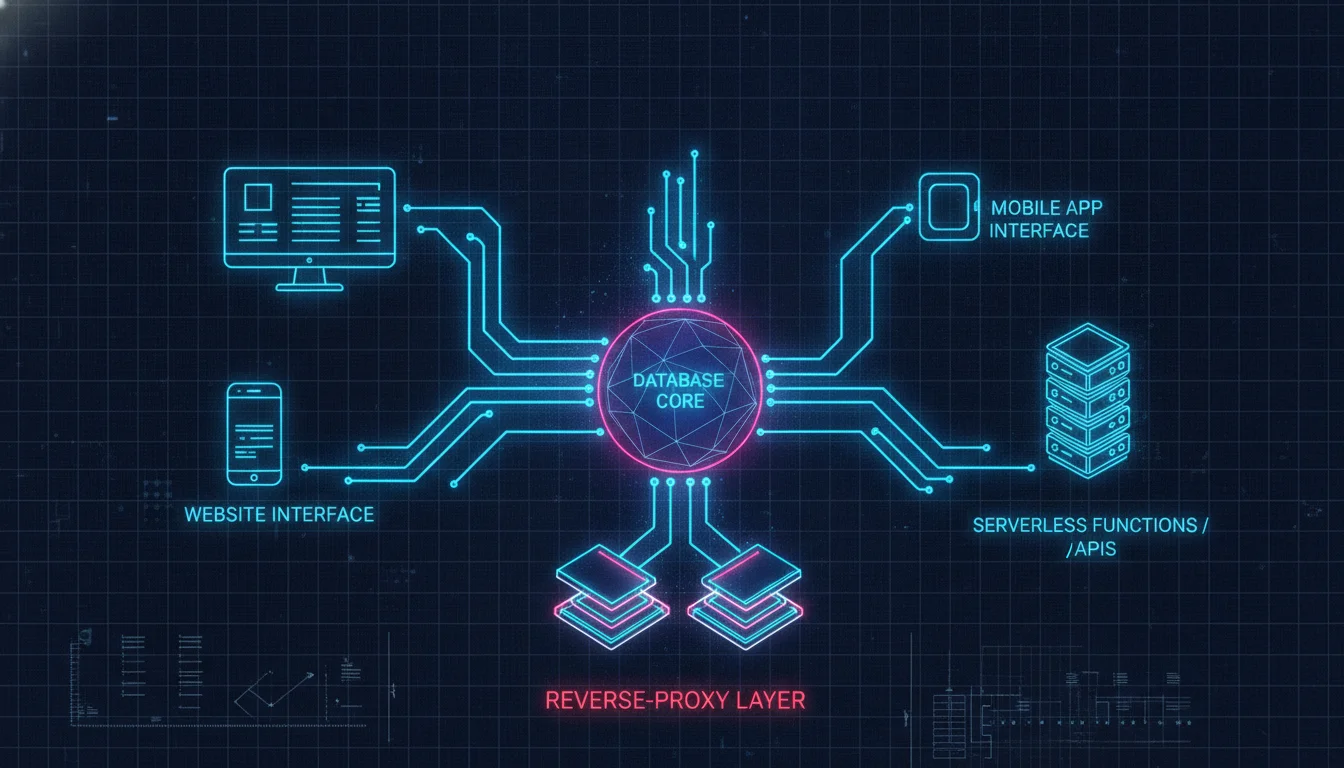
Overcoming Platform Constraints: The Reverse Proxy Architecture
While visual development platforms like Webflow offer superior design flexibility, they possess severe infrastructural limitations when subjected to the sheer scale of programmatic SEO. The most prominent constraint is Webflow’s strict limitation of 10,000 CMS items on standard plans. For an affiliate programmatic strategy attempting to generate pages for every zip code in the United States, every possible software integration permutation, or thousands of specialized directory listings, a 10,000-page ceiling is immediately prohibitive.
To bypass this limitation without migrating to enterprise tiers, technical SEOs deploy sophisticated reverse proxy architectures. A reverse proxy serves as an intermediary server that sits between the end user and multiple backend systems. In a programmatic SEO context, the reverse proxy allows the site owner to host the core marketing pages, homepages, and standard editorial content natively on Webflow, while seamlessly serving an infinite number of programmatically generated pages from a separate, highly scalable headless infrastructure, all stitched together under the same primary domain.
The implementation of a reverse proxy typically requires routing edge requests via platforms like Cloudflare Workers. The Cloudflare Worker script evaluates the incoming HTTP request. If the request points to the root domain or standard paths, it fetches the response directly from Webflow. However, if the request matches a specific subfolder path designated for the programmatic data, the Worker intercepts the request and fetches the pre-rendered HTML from a static site generator like Next.js connected to a Supabase backend. Platforms like Subfold automate this exact process, allowing no-code operators to configure subdirectory routes and manage DNS settings without writing custom JavaScript logic at the edge.
This reverse proxy architecture introduces specific technical SEO risks that require meticulous mitigation. Because the final page is being stitched together from disparate servers at the edge, canonical tag discrepancies frequently occur. Webflow’s native environment may inadvertently generate canonical tags pointing to its internal staging domain rather than the primary production URL. If the reverse proxy script does not dynamically parse the HTML head and rewrite these canonical tags before delivering the payload to the client, search engine crawlers will misattribute the ranking signals or ignore the programmatic pages entirely.
Furthermore, URL pathing must be strictly managed.
Webflow natively converts slashes to hyphens within CMS slugs, preventing the creation of deeply nested, logical folder structures (e.g., /services/web-design/fintech becomes services-web-design-fintech). By moving the programmatic generation to an external backend while utilizing a reverse proxy, architects regain total control over the URL taxonomy, allowing for perfectly structured silo architectures. Alternatively, if SEO indexing is entirely unnecessary for a specific dataset, architects can utilize the WWX stack (Webflow + Wized + Xano) to load millions of records entirely client-side, bypassing the CMS limit without triggering crawl issues.
Large Language Models and Automated Content Orchestration
The integration of Large Language Models (LLMs) has fundamentally transformed the content generation phase of programmatic SEO. Historically, programmatic pages relied heavily on rigid, spun text algorithms that resulted in robotic, unnatural phrasing, leaving the site vulnerable to algorithmic quality penalties. Today, by utilizing APIs from OpenAI, Anthropic, or proprietary models, architects can dynamically generate highly contextual, grammatically flawless narrative descriptions for thousands of rows of tabular data.
Effective LLM integration relies less on the choice of the model itself and almost entirely on the sophistication of prompt engineering and automated prompt enrichment pipelines. A poorly designed prompt will yield algorithmic hallucinations, repetitive syntactic structures, and generic “fluff” that search engines actively suppress. The optimal workflow rigidly separates instructions into system prompts and user prompts. System prompts dictate the fundamental behavior, output formatting, tone, and logical constraints of the model. For example, a system prompt managed through an integration layer like Kubernetes AgentGateway might explicitly instruct the LLM: role: system, content: “Parse the unstructured text into CSV format” or command the model to adopt a specific expert persona while strictly limiting output length. The user prompt then supplies the specific row of data or context from the database to be processed dynamically.
In a production environment, developers utilize frameworks like LangChain and LangGraph to automate this multi-step cognitive pipeline, while building interfaces with tools like Streamlit. An automated Python script reads the cleansed CSV dataset iteratively. LangChain orchestrates the flow, sending specific variables (e.g., city name, population, local weather metrics) to the LLM alongside a highly engineered prompt library. Rather than asking the LLM to simply “write an article,” sophisticated prompts utilize frameworks like the “5Ws and H” (Who, What, Where, When, Why, How).
A high-performance prompt instructs the LLM to generate an “answer-first” introductory paragraph of exactly 40 to 60 words that clearly resolves the primary search intent in plain language. This is followed by specific H2 subheadings that mirror common user search queries (e.g., “How much does cost,” “What are the alternatives to”). To optimize for both traditional search and emerging LLM-driven search engines—a discipline known as Generative Engine Optimization (GEO)—the content must adhere to strict semantic guidelines. Prompts force the LLM to output well-structured HTML, utilizing proper H1, H2, and H3 hierarchies, maintaining short paragraph lengths of two to four sentences, and employing descriptive bullet points for scannability. Furthermore, providing the LLM with instructions to generate FAQ schema markup directly within the response ensures that the resulting programmatic pages are eligible for rich snippets and easily digestible by machine learning algorithms.
To build topical authority that modern LLMs respect, architects implement the ACE Audit Framework (Assess, Consolidate, Enrich):
- Assess: Determine if top LLMs already cite the domain for core queries by sampling responses and assessing source footprints on high-authority hubs.
- Consolidate: Merge near-duplicate articles and standardize naming conventions (e.g., ensuring “BlogSEO” is not fragmented as “Blog SEO”) so embedding algorithms accurately map the brand entity.
- Enrich: Apply exhaustive structured data (Article, FAQ, HowTo, Product schemas), and include isAccessibleForFree tags to signal that the content is not paywalled.
Operators must also navigate Context Windows (typically 2K to 8K tokens) by chunking long pages into semantic sub-headers and placing one key verifiable statistic per paragraph, as LLMs struggle to extract data buried in unstructured text or untagged infographics. Incorporating sameAs links pointing to authority profiles like Wikidata, Crunchbase, or LinkedIn ensures the LLM’s knowledge graph perfectly maps the publisher’s brand. If proprietary data must be shielded from LLM ingestion while remaining visible to traditional search engines, the tag is deployed.
Despite the power of LLMs and Retrieval-Augmented Generation (RAG) applications powered by vector databases like Pinecone, total automation without human oversight remains a high-risk strategy. Search engines intensely emphasize the principles of Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T). Pages comprising entirely AI-generated text without verifiable, unique data points are immediately classified as thin content. Therefore, the LLM should be utilized strictly as a linguistic engine to weave unique, proprietary database statistics into readable prose, rather than relying on it to hallucinate facts or formulate unsubstantiated opinions.
Internal Linking Topologies and Crawlability Optimization
As a programmatic SEO site expands from hundreds to tens of thousands of pages, the internal linking architecture transitions from a UX consideration to the most critical determinant of indexing success. If search engine crawlers cannot efficiently discover, parse, and navigate the massive network of dynamically generated URLs, the content will languish in server logs as unindexed orphan pages.
The primary strategy for managing massive page volumes is the implementation of a strict hierarchical, hub-and-spoke linking topology. In this architectural model, the homepage does not attempt to link to every programmatic iteration, which would immediately dilute page authority. Instead, it links to high-level, static category pages, known as hubs. These hubs aggregate links to a specific semantic subset of programmatic pages. For example, in a travel affiliate site, the homepage links to a “Hotels by State” hub, which links downward to a “Hotels in New York” sub-hub, which subsequently links to the individual programmatic neighborhood pages like “Hotels in Brooklyn”. This hierarchical structure ensures a shallow click depth, guaranteeing that any page deep within the programmatic cluster can be reached within three to four clicks from the root domain.
Horizontal cross-linking is equally imperative for contextual relevance. Programmatic templates must be engineered to include dynamic “Related Items” modules at the conclusion of the page body. By utilizing database reference fields within the CMS, the template automatically generates contextual links to sister pages. For instance, a programmatic page detailing “CRM integrations for Shopify” should natively cross-link to “Email marketing integrations for Shopify” and “CRM integrations for Magento.” This logic facilitates lateral crawler movement, distributing passing link equity horizontally across the cluster and establishing deep semantic relevance.
Breadcrumb navigation serves as a secondary, automated mechanism for site architecture reinforcement. Implementing structured breadcrumbs on every programmatic page provides a guaranteed upward path for search engine bots, clarifying the site hierarchy and returning the crawler to higher-authority hub pages without relying solely on main navigation. Crucially, all internal links must utilize descriptive, keyword-rich anchor text natively pulled from the database, completely avoiding generic directives such as “click here” or “read more”.
Finally, for platforms like Webflow where complex logic may be restricted, generating static HTML sitemap pages and linking to them directly from the global footer guarantees that crawlers have an uninterrupted, JavaScript-free entry point to discover every URL generated by the database.
Technical SEO: Crawl Budget Management and Server Efficiency
When executing programmatic SEO strategies resulting in 10,000 to over 1,000,000 unique URLs, technical optimization transitions from a general best practice to a strict operational requirement. At this scale, the primary algorithmic limiting factor is the search engine’s “crawl budget”—the finite amount of time, processing power, and server requests a search engine bot allocates to crawling a specific domain during a given timeframe. If the crawl budget is exhausted on inefficient operations, newly generated high-value pages will not be discovered or indexed. Approximately 40% to 60% of large enterprise websites suffer from severe crawl inefficiencies, unknowingly blocking their own revenue-generating pages from the SERPs.
Optimizing the crawl budget requires a multifaceted technical approach focused on server speed, error mitigation, payload reduction, and strict directive control. As technical SEO experts note, “You are what Googlebot eats”; if Google misses content due to an unoptimized crawl budget, search visibility becomes mathematically impossible.
First, server response time is the most direct influencer of the crawl rate limit. Search engine algorithms dynamically adjust their crawl frequency based on the host server’s load capacity.
If the server responds swiftly without timing out, the crawler will significantly increase its request volume, sometimes jumping from 150,000 to 600,000 crawled URLs per day following a speed optimization update. Conversely, sluggish response times prompt the crawler to aggressively throttle its activity to avoid crashing the host site. Therefore, implementing aggressive caching strategies, minimizing heavy dynamic database queries on page load, executing asset compression (like converting images to AVIF or WebP), and enabling Gzip or Brotli compression at the server edge are mandatory steps. Gzip compression does not inherently alter the crawl budget allocation, but it dramatically accelerates the download speed over the protocol, allowing the bot to parse the payload faster and move on to subsequent URLs.
| Crawl Budget Element | Implementation Best Practice | Technical Rationale |
|---|---|---|
| XML Sitemaps | Maximum 50,000 URLs per file; Maximum 50MB uncompressed size. | Adheres to strict HTTP protocol limits; ensures complete XML parsing without timeouts. |
| ** |
Only update index files when meaningful structural or content changes occur. | Triggers crawler prioritization; false updates degrade trust and waste crawl cycles. |
| Status Codes | Remove all 404/410 URLs from sitemaps immediately. | Including non-existent pages forces the crawler into dead ends, wasting finite budget. |
| Canonical Directives | Ensure Sitemap URLs perfectly match the page canonical declarations. | Prevents the crawler from downloading duplicate variants, saving space and consolidating equity. |
Second, eliminating dead-end requests is vital for preserving crawl efficiency. If an affiliate product is discontinued or a dataset is pruned, the corresponding programmatic page must return a definitive 404 (Not Found) or 410 (Gone) HTTP status code. Soft 404s—pages that visually display a “not found” message to the user but return a successful 200 OK status to the server—are catastrophic at scale, as they force the crawler to continually re-evaluate useless content, hemorrhaging valuable budget. Similarly, redirect chains must be strictly limited to a single hop (1-2 maximum); multi-step redirects consume excessive crawl resources, trigger timeout thresholds, and heavily dilute passing link equity.
Third, precise control over what the crawler is permitted to access must be enforced using robots.txt files and meta robots tags. Low-value generated pages, internal search result parameters, and dynamic filtering URLs create infinite crawl spaces known as index bloat. These infinite tracking and sorting parameters must be explicitly blocked in the robots.txt file, or handled via strict self-referencing canonical tags, ensuring the search engine focuses exclusively on the canonical, revenue-generating URLs without getting trapped in algorithmic spider traps.
The deployment phase must also be carefully managed to avoid triggering spam filters. Deploying 100,000 pages instantaneously can overwhelm both the origin server and the search engine’s ingestion capacity, leading to latency timeouts and a stalled indexing pipeline. Programmatic pages should be published in calculated, measured batches, allowing technical teams to closely monitor server logs and Google Search Console coverage reports to identify and rectify 4xx errors, canonical mismatch warnings, or unindexed anomalies before the subsequent batch is deployed.
Vertical Executions and Affiliate Teardowns
The theoretical mechanics of programmatic SEO are only as valuable as their commercial application. By mapping robust datasets to high-conversion intent, affiliate marketers can dominate lucrative sectors that remain too fragmented for traditional editorial teams to cover comprehensively. Analyzing the metrics and Conversion Rate Optimization (CRO) tactics of highly successful affiliate sites provides a blueprint for programmatic deployment.
| Affiliate Site | Primary Niche | Estimated Organic Traffic | Total Indexed Pages | Notable Metrics & Valuations |
|---|---|---|---|---|
| Nerd Wallet | Personal Finance | 17,100,000 | 17,775 | Raised $130.5M; $1.2 Billion Valuation |
| The Spruce | Home Decor / DIY | 19,500,000 | 15,770 | Massive growth via 301 redirects from About.com |
| Tom’s Hardware | Technology / Computing | 3,500,000 | 34,227 | 25+ year domain authority; 56,959 referring domains |
| Gear Lab | Outdoor Equipment | 2,000,000 | 6,822 | Dominates through exhaustive “mega-post” comparisons |
| The Penny Hoarder | Personal Finance | 496,000 | 6,003 | Acquired for $102.5 Million in 2020 |
| Baby Gear Lab | Parenting / Baby Products | 290,000 | 1,057 | Leveraged strong medical E-A-T signals early on |
| Embora Pets | Pet Care | 99,600 | 806 | Sold for $60,000; earned $2k/month via display ads |
| Own The Yard | Outdoor / DIY | 59,400 | 637 | 8,091 referring domains; monetized via Amazon & Ezoic |
An analysis of these highly profitable properties reveals several structural commonalities that drive their economic engines. First, they balance massive scale with deep informational value, mixing highly commercial pages with thousands of informational queries to dilute the risk of algorithmic penalties. Second, they explicitly leverage Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T) by prominently featuring author credentials, leveraging expert reviewers, and building brandable domain names that generate substantial direct traffic independent of search engines.
From a conversion standpoint, analyzing these properties yields highly specific, actionable CRO insights applicable to any programmatic template:
- Comparison Tables Above the Fold: Placing mobile-responsive product comparison tables at the absolute top of the article, before extensive prose, is statistically one of the most effective methods for increasing outbound affiliate clicks.
- Infinite Scroll Implementation: For sites monetizing via display ads, implementing infinite scroll dramatically increases the aggregate page views and total ad impressions per session, directly multiplying revenue without requiring additional unique visitors.
- Psychological CTA Alterations: Changing basic call-to-action anchor text from aggressive phrasing like “Buy Now on Amazon” to softer, investigative phrasing like “Check Price on Amazon” significantly increases the click-through rate, moving the user down the funnel more efficiently. Furthermore, ensuring these CTA buttons utilize drastic, highly contrasting colors rather than blending into the site’s aesthetic theme prevents banner blindness and captures visual attention.
Beyond traditional content sites, pure programmatic models exhibit staggering growth vectors. Omnius AI, an artificial intelligence image generator platform, deployed a fully automated programmatic SEO engine targeting specific use cases. Within ten months, the implementation drove monthly signups from a stagnant 67 to over 2,100—a 3,035% conversion increase driven entirely by matching hyper-specific queries with dynamically generated landing pages. Similarly, the travel and tourism sector relies heavily on this architecture. Visit Atlantic City achieved a massive 661% year-over-year increase in organic traffic by consolidating fragmented data into a cohesive, programmatic entity. WorldPopulationReview.com leverages data templating across 36,000 pages to generate nearly 9 million monthly visits, utilizing dynamically updated charts and tables to secure over 36,000 dofollow referring domains. Nomad List applies this concept to the digital nomad niche, algorithmically generating pages detailing the cost of living, internet speeds, and safety metrics for thousands of global municipalities without relying on manually written copy.
In the high-yield personal finance and insurance sectors—where a 2020 Bank of America survey noted that 75% of millennials prioritize retirement planning and 51% prioritize emergency funds—programmatic templates provide unmatched utility. Italian pet insurance startup ConTe.it Assicurazioni Cane e Gatto utilized sophisticated segmentation via HubSpot to align their programmatic landing pages with distinct user behaviors, dramatically increasing click-through and conversion rates. The complexity and localization of financial products mean that a user searching for common health issues requires an entirely different page structure than a user searching for average insurance costs. By aggregating veterinary data regarding genetic predispositions and merging it with live quote APIs, the affiliate publisher delivers highly personalized risk assessments natively within the programmatic template.
In all vertical executions—from the $240.9 billion dietary supplement market to enterprise SaaS comparisons—the integration of structured data markup is an absolute necessity. By wrapping the programmatic content in precise JSON-LD tags, the affiliate site translates its raw database into a machine-readable format. Achieving a rich snippet display featuring star ratings, price ranges, and FAQ drop-downs dramatically increases organic visibility, amplifying the economic return of the entire programmatic operation.
Strategic Conclusions
The maturation of programmatic SEO marks a definitive and irreversible shift in digital acquisition strategies. For niche affiliate publishers, the competitive advantage no longer lies solely in creative editorial output, but in data engineering, prompt orchestration, and infrastructural scalability.
Strategic Implementation and Scalability
By transitioning from a paradigm of linear manual labor to sophisticated systems architecture, marketers can unlock entirely new stratums of low-volume, high-converting search intent.
To execute this effectively, web architects must prioritize the absolute integrity of the underlying database, utilizing advanced cleansing techniques through Python Pandas and OpenRefine to ensure faultless data injection. The technological stack must be meticulously configured to bypass platform limitations, leveraging headless frameworks and reverse proxies to scale infinitely without fracturing domain authority. Furthermore, the deployment of Large Language Models must be tightly constrained by rigid system prompts and the ACE framework, preventing generative hallucinations and ensuring that every programmatic page delivers unique, structured value that complies with evolving search algorithms.
Commercial Success and Conversion
Ultimately, the commercial success of a programmatic SEO endeavor depends entirely on rigorous technical discipline. By maintaining strict control over internal linking topologies and relentlessly optimizing the server’s crawl budget capacity through payload reduction and directive management, publishers ensure their expanding content matrices are efficiently ingested and indexed. When applied to highly profitable, attribute-heavy niches like software integration, localized travel, personal finance, or specific insurance modalities, programmatic SEO transcends simple traffic acquisition, functioning instead as a highly calibrated, automated engine for exponential, high-margin conversion growth.


