AWS vs Google Cloud: E-commerce Hosting TCO Analysis
Executive Summary and Macroeconomic Context

In the highly competitive digital retail sector, cloud infrastructure decisions dictate not only technical scalability but also underlying corporate profit margins. High-traffic e-commerce platforms face unique, punishing architectural challenges: extreme traffic volatility driven by promotional events like Black Friday, hyper-latency-sensitive transaction pipelines that directly correlate to cart abandonment rates, and the non-negotiable requirement for global, edge-optimized content delivery. Choosing the most cost-effective cloud provider to support these workloads requires an analysis that extends far beyond a superficial comparison of raw virtual machine unit pricing. The true total cost of ownership (TCO) is derived from the complex intersection of baseline compute rates, underlying network topologies, automated versus manual discounting mechanisms, and the human operational labor required to maintain the architecture.
As the industry navigates through 2025 and into 2026, the global public cloud infrastructure market continues to expand at a staggering pace, with total cloud spending forecast to exceed $675 billion annually. The market remains definitively structured as an oligopoly. Amazon Web Services (AWS) retains its dominant position, commanding approximately 29% to 32% of the global cloud infrastructure market. Microsoft Azure holds the secondary position with approximately 20% to 23% of the market share. Google Cloud Platform (GCP) maintains the third position, controlling roughly 11% to 13% of the market. However, beneath these static market share percentages lies a dynamic shift in momentum. Google Cloud Platform is currently demonstrating the highest year-over-year growth rate among the major hyperscalers, expanding at 34%, driven largely by aggressive enterprise pricing strategies, advanced integrated data analytics capabilities, and its dominant positioning in artificial intelligence and machine learning infrastructure.
For technical decision-makers architecting e-commerce platforms, 2025 introduced unprecedented pricing volatility. The top three cloud providers invested a combined $240 billion into data center and AI infrastructure expansion, pushing quarterly capital expenditures to $87 billion. To subsidize these massive hardware acquisitions, hyperscalers quietly introduced targeted price hikes that function as a hidden “AI tax” on standard digital commerce workloads. AWS significantly increased cross-region data transfer costs by 25% to 40% and doubled inter-Availability Zone data transfer fees. Microsoft Azure increased the cost of premium solid-state storage arrays by 10% to 11%. GCP executed visible price hikes across its Workspace bundles by 20% to 34% to subsidize the bundling of its Gemini AI models. Consequently, a standard 4-CPU, 16GB virtual machine that ostensibly costs between $88 and $96 per month on paper can easily generate a bill twice that size once hidden network egress, storage tiering, and cross-region traffic penalties are fully calculated.
Cost optimization in this volatile domain requires a granular understanding of disparate pricing philosophies. E-commerce TCO comparisons between AWS and GCP reveal a complex landscape of trade-offs. AWS offers unparalleled architectural granularity and an ecosystem optimized for migration flexibility, allowing monolithic legacy systems to transition to the cloud with minimal friction. Conversely, GCP optimizes for operational simplicity and cloud-native architectural paradigms, frequently delivering 19% to 22% lower total costs for specific modern, distributed workloads through automated discount mechanisms and superior default networking. This exhaustive report deconstructs the structural, financial, and operational variables that dictate cloud hosting costs for high-traffic e-commerce environments, providing a definitive framework for infrastructure optimization in 2026.
Architectural Philosophies and the Economics of Abstraction
The fundamental divergence between AWS and GCP lies in their core architectural abstraction philosophies. This philosophical divergence directly impacts the daily workflows of platform engineers, dictating developer productivity and the consequent human capital costs associated with infrastructure management.
Amazon Web Services provides compute services across highly granular, multi-layered abstraction levels. E-commerce engineering teams can provision Amazon Elastic Compute Cloud (EC2) instances for low-level, operating-system-level control, transition upward to container orchestration via Amazon Elastic Kubernetes Service (EKS) or Amazon Elastic Container Service (ECS), and ultimately refactor application code into pure serverless execution models utilizing AWS Lambda and AWS Fargate. This deeply layered approach is highly strategic for enterprise migrations. It permits organizations to execute a “lift-and-shift” strategy, moving legacy on-premises e-commerce applications to EC2 virtual machines without requiring immediate, prohibitive code rewrites. Teams can then gradually modernize the architecture over a multi-year horizon. However, this extensive configurability introduces massive operational overhead. AWS architecture demands the precise, manual orchestration of Virtual Private Clouds (VPCs), complex subnet segmentations, customized routing tables, and granular Identity and Access Management (IAM) security groups. The administrative burden of managing this complexity directly translates to higher DevOps staffing requirements.
Conversely, Google Cloud Platform enforces higher levels of operational abstraction by default. Services such as Google Cloud Run, GKE Autopilot, and managed instance groups intentionally obscure the underlying infrastructure. GCP reduces infrastructure visibility in favor of aggressive, automated scaling and operational simplicity. The platform heavily favors cloud-native, containerized, and microservices-based deployment models. For an e-commerce platform built on modern, scalable paradigms from inception, GCP drastically reduces the DevOps engineering burden. While some users report that GCP’s advanced networking configuration interface can present a steep initial learning curve, the platform’s overarching design minimizes routine infrastructure maintenance. This reduction in human capital cost is a critical factor that is frequently excluded from raw compute pricing calculators, yet it significantly impacts the total cost of ownership over a multi-year product lifecycle.
A critical, mathematically quantifiable distinction also exists in the underlying network architecture of the two providers. AWS Virtual Private Clouds are inherently region-specific constructs. Constructing a globally distributed, highly available e-commerce platform on AWS requires complex peering connections, Transit Gateway configurations, and explicit routing protocols. Data transfer between these regional VPCs incurs strict, unavoidable financial penalties. Google Cloud’s VPCs are global by default, utilizing Google’s premium, private fiber-optic global network backbone. A single GCP VPC can natively span all global regions. This architectural elegance drastically simplifies the deployment of multi-region high-availability e-commerce architectures, mitigating the administrative complexity of global traffic routing and frequently reducing the inter-region bandwidth fees that plague complex AWS deployments.
Compute Infrastructure: Hardware Innovation and Virtual Machine Economics
Compute resources generally constitute the foundational expense of an e-commerce cloud deployment, powering the application web servers, background microservices, inventory management cron jobs, and order processing workers. Both AWS and GCP offer an exhaustive array of virtual machine families tailored to specific memory, CPU, and storage ratios. However, their approaches to underlying hardware innovations and financial discount mechanisms differ profoundly.
Custom Silicon and Price-Performance Yields
To combat cloud commoditization and reduce dependency on traditional x86 processor manufacturers, both hyperscalers have invested heavily in custom silicon engineering. AWS has maintained a multi-year lead in this domain, aggressively iterating on its ARM-based Graviton processors. The introduction of the Graviton4 processors in late 2024 and 2025, which power the M8g, C8g, and R8g instance families, represents a paradigm shift in compute economics. Built on the AWS Nitro System and utilizing DDR5 memory architectures, Graviton4 instances deliver up to a 40% absolute performance improvement and up to a 29% better price-performance ratio compared to the preceding Graviton3 instances.
For compute-intensive e-commerce operations, the advantages of custom ARM silicon are highly measurable. Comprehensive Sysbench testing—a multi-threaded benchmarking tool designed to evaluate core database and CPU performance—demonstrates that transitioning from Graviton2 (m6g) to Graviton4 (m8g) yields exponential gains. When deploying relational databases on these instances, engineering teams can achieve up to 165% higher throughput, up to 120% better price-performance ratios, and an 80% reduction in application response times. Furthermore, for background asynchronous tasks critical to modern e-commerce—such as bulk video encoding for rich product listings—Graviton4 instances perform 12% to 15% better than Graviton3, securing top placements in price-performance benchmarking against all available instance types.
GCP has countered this architectural dominance with its custom Intel architectures (the C3 instance family) and its own proprietary ARM-based Axion processors.
Performance benchmarking between AWS Graviton4 and GCP Axion reveals nuanced hardware optimizations
While AWS Graviton4 instances consistently demonstrate higher raw Requests Per Second (RPS) in parallel, high-throughput workloads due to their tight integration with the underlying AWS Nitro System, Google’s Axion processors excel in latency-sensitive operations. Testing indicates that Axion instances deliver noticeably lower P99 tail latencies, suggesting a highly optimized core design and cache structure. For an e-commerce checkout flow where sub-millisecond response times prevent cart abandonment, this latency advantage is theoretically compelling. However, AWS’s multi-generational lead in Graviton deployment provides a significantly broader array of instance sizes, deeper software ecosystem compatibility, and more predictable cost-reduction pathways for organizations seeking immediate ARM-driven financial optimization.
Commitment Discounts versus Sustained Use Automation
The divergence in pricing philosophies is most overtly apparent in how both providers incentivize and reward long-term compute usage. Hyperscaler pricing models are notoriously complex, blending flat-rate elements with metered, consumption-based billing designed to maximize provider yield.
AWS relies primarily on a rigid, customer-initiated commitment model enforced through Reserved Instances (RIs) and modern Savings Plans (SPs)
E-commerce organizations can achieve massive discounts of up to 72% off standard on-demand rates by financially committing to the platform over a strict 1-year or 3-year term. AWS offers multiple tiers of commitment. EC2 Instance Savings Plans offer the deepest discounts but lock the customer into specific instance families and geographical regions. Compute Savings Plans offer a slightly lower discount ceiling but provide flexibility across EC2, Fargate, and Lambda deployments regardless of instance size or region.
While these discounts are lucrative, maximizing their value requires highly mature financial operations (FinOps) and precise capacity forecasting. A minor architectural miscalculation—such as purchasing an RI for a Linux operating system while running a Windows workload, or committing to the us-east-1a availability zone while the auto-scaling group spins up instances in us-east-1b—will result in the discount failing to apply, leading to catastrophic and unexpected on-demand billing spikes. Furthermore, AWS SPs and RIs require the customer to actively manage the financial instrument, tracking utilization and coverage rates relentlessly.
Google Cloud Platform offers a hybrid approach to compute discounting that is inherently more forgiving to dynamic workloads
First, GCP provides Spend-Based Committed Use Discounts (CUDs). By committing to a baseline hourly spend for a 1-year or 3-year term, customers receive up to a 57% discount on Compute Engine resources. While the maximum theoretical discount depth is shallower than AWS’s 72%, GCP’s CUD pricing structure is simpler and highly flexible across custom machine types.
More importantly, GCP automatically applies Sustained Use Discounts (SUDs) to resources running for a significant portion of the billing month. A virtual machine running continuously for a full billing cycle automatically receives a discount of up to 30% without requiring any upfront financial commitment, long-term contract, or administrative action from the engineering team. For rapidly scaling e-commerce platforms dealing with unpredictable baseline traffic, GCP’s automatic SUDs act as an inherent financial safety net. They eliminate the massive financial risk of over-committing to rigid 3-year contracts, providing substantial operational savings out-of-the-box simply by running the necessary infrastructure. This dynamic frequently results in GCP virtual machines being 9% to 50% less expensive than AWS equivalents for highly variable workloads that cannot safely commit to 3-year SPs.
| Discount Mechanism | AWS Savings Plans / Reserved Instances | GCP Committed Use Discounts (CUD) |
|---|---|---|
| Maximum Compute Discount | Up to 72% | Up to 57% |
| Standard Commitment Terms | 1 year or 3 years | 1 year or 3 years |
| Automatic Usage Discounts | None (Requires proactive purchase) | Up to 30% (Sustained Use Discounts) |
| Workload Flexibility | High (Compute SPs span EC2/Fargate/Lambda) | Medium (Spend-based across Compute Engine) |
| Payment Structure Options | No upfront, Partial upfront, All upfront | No upfront payment required natively |
| Cancellation/Modification | Standard RIs can be sold on Marketplace; SPs are inflexible | Generally inflexible once committed |
=>
Table 1: Comparative Analysis of Compute Commitment Discount Models
The Economics of Ephemeral Capacity: Spot and Preemptible Instances
For stateless e-commerce components—such as image resizing workers, batch asynchronous order processors, or highly distributed, containerized web frontends capable of rapid, graceful termination—both platforms offer access to excess data center capacity at staggering discounts. AWS Spot Instances and GCP Preemptible VMs (alongside their newer Spot VMs) provide up to 90% to 91% savings compared to standard on-demand rates.
Leveraging these ephemeral instances within auto-scaling groups or Kubernetes clusters is an absolutely mandatory FinOps strategy for high-traffic retail environments. By architecting the application to withstand sudden node terminations—a core principle of cloud-native design—engineering teams can handle massive Black Friday flash sales or holiday traffic spikes using hardware that costs pennies on the dollar. AWS Spot Instances offer sophisticated bidding strategies and diverse capacity pools, while GCP Preemptible VMs enforce a strict 24-hour maximum lifespan, forcing architects to actively design for continuous node rotation.
Storage Economics and Lifecycle Optimization
Modern e-commerce platforms generate petabytes of data, ranging from user-generated content and product review imagery to compliance-mandated transaction logs. Understanding the pricing nuances between block storage (attached to virtual machines) and object storage (for massive unstructured data) is vital.
Object Storage Tiers
AWS Amazon Simple Storage Service (S3) and Google Cloud Storage (GCS) offer highly durable, infinitely scalable object storage. The baseline pricing is highly competitive but contains subtle variations. In US regions, Google Cloud Storage Standard tier is priced at $0.020 per GB-month. AWS S3 Standard tier in US regions is priced slightly higher at $0.023 per GB-month for the initial 50TB of storage, with tiered volume discounts applied thereafter.
However, true cost optimization in object storage relies on sophisticated lifecycle management—automatically moving data that is infrequently accessed to colder, cheaper storage tiers. AWS offers a highly mature ecosystem with S3 Standard-Infrequent Access (IA) priced at $0.0125 per GB-month, S3 Glacier for archival data at $0.004 per GB-month, and S3 Glacier Deep Archive representing the absolute lowest cost at $0.00099 per GB-month. GCP provides equivalent mechanisms with its Nearline, Coldline, and Archive tiers, allowing organizations to slash storage costs for compliance logs or legacy product imagery. For e-commerce platforms managing massive historical catalogs, AWS S3 is generally recognized as the most mature option due to its wide range of third-party integrations and granular lifecycle policies, while GCP offers seamless, native multi-region replication that appeals to globally distributed applications.
Block Storage Optimization
Block storage—the virtual hard drives attached to compute instances—frequently harbors massive invisible costs. E-commerce platforms running relational databases or stateful applications on EC2 or Compute Engine require high-performance IOPS (Input/Output Operations Per Second). In AWS, a common source of wasted capital is the retention of legacy storage types. Migrating from older gp2 Elastic Block Store (EBS) volumes to the modern gp3 standard can instantly reduce block storage costs by up to 40% per gigabyte, while simultaneously allowing engineers to provision IOPS and throughput independently of the total storage volume size.
Furthermore, block storage requires rigorous hygiene. Terminating an EC2 instance does not automatically delete the attached EBS volume unless explicitly configured to do so. Large e-commerce deployments frequently bleed thousands of dollars monthly paying for “orphaned” EBS volumes holding stale data for servers that no longer exist. Advanced FinOps practices involve continuous automated scanning to identify and purge these unattached resources.
Networking Economics: The Egress Trap and Content Delivery
In modern digital commerce, rich media assets (such as high-resolution product carousels, 3D model viewers, and video demonstrations), heavy API JSON payloads, and globally distributed user bases generate immense volumes of outbound data traffic.
Egress Penalties and the High Availability Tax
Egress fees—the cost of transferring data out of the cloud provider’s network to the public internet—are universally acknowledged as the most underestimated and punitive line item in an enterprise cloud budget.
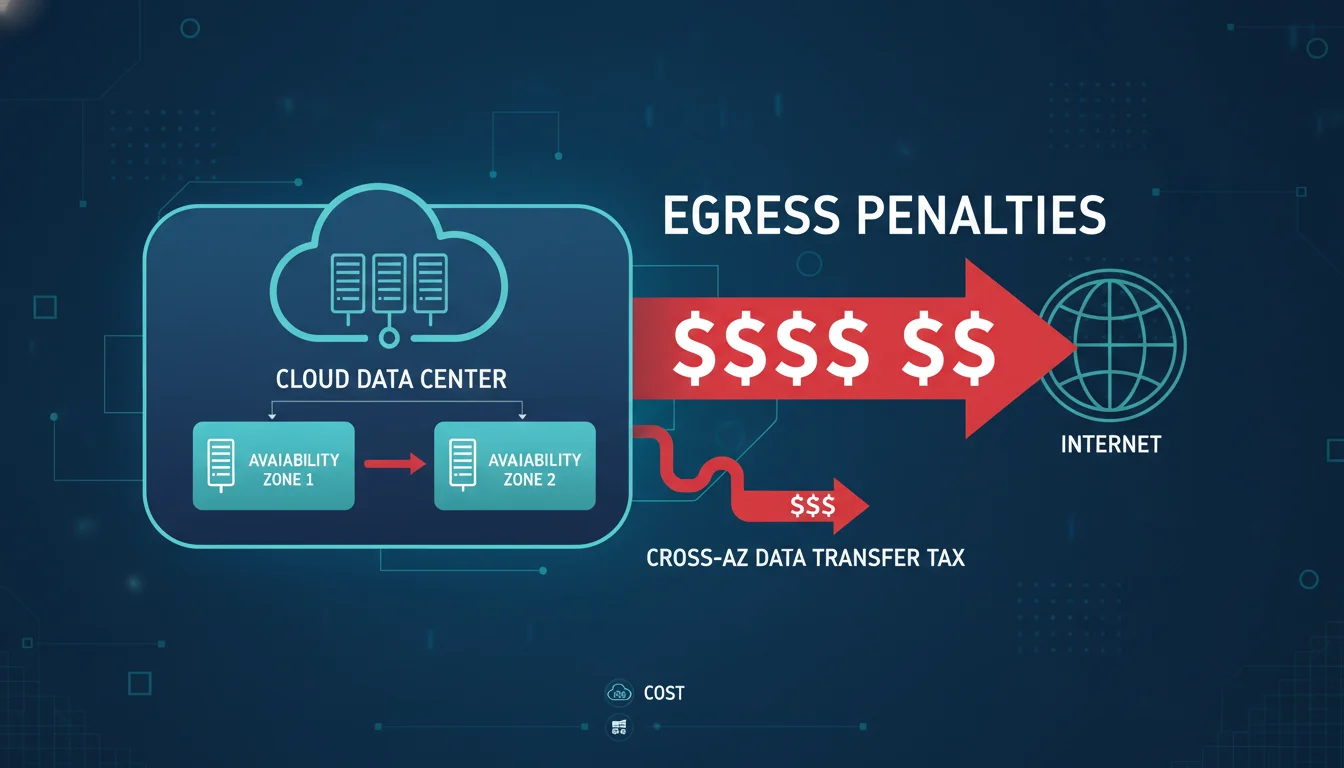
Both AWS and GCP utilize a highly asymmetric pricing model for bandwidth: incoming data (ingress) is entirely free, encouraging organizations to upload their data seamlessly. However, the moment that data is served to an end-user, steep baseline egress rates apply.
In standard US regions, AWS charges $0.09 per GB for the first 10TB of outbound internet traffic per month, with marginal rate reductions applied at exponentially higher volumes. Google Cloud Platform charges a more aggressive baseline of $0.12 per GB for the first gigabyte, making it slightly more expensive for lower-volume operations. To contextualize these costs, a mid-sized e-commerce application requiring 10TB of monthly outbound data transfer could face an additional $870 to $1,200 in pure egress fees before accounting for a single CPU cycle or storage byte.
At a massive enterprise scale, the hyperscaler egress premium becomes staggering. Modeling an e-commerce platform pushing 50TB of pure internet egress per month illustrates the financial severity. Ignoring nominal free tiers, 50TB of egress will cost approximately $4,500 on AWS and $4,250 on GCP. Comparing this to alternative infrastructure providers underscores the premium charged by the big three: the identical 50TB of transfer would cost roughly $500 on DigitalOcean, $425 on Oracle Cloud, and a mere $56 on Hetzner.
Furthermore, AWS advertises competitive outbound internet rates but buries a punitive “tax on high availability” deep within its VPC architecture. To build a fault-tolerant, resilient e-commerce backend, cloud architects are practically mandated to deploy resources across multiple Availability Zones (AZs) within a region. AWS strictly penalizes this intra-region, inter-AZ traffic, charging between $0.01 and $0.02 per GB for data moving between zones. If an e-commerce site operates a highly available active-active microservice mesh, or continuously synchronizes terabytes of database replication data across AZs to prevent data loss, it will incur hundreds or thousands of dollars in hidden network charges. An architecture moving 1TB of monthly traffic between availability zones faces an immediate $10 to $20 monthly surcharge—an architectural tax that Google Cloud Platform and Microsoft Azure frequently waive or subsidize for native services.
Operational patterns frequently exacerbate these egress costs unexpectedly. Organizations routinely exhaust modest free tier allowances (such as AWS’s 100GB/month free tier) within hours of a code deployment. Development and testing environments that clone production databases for staging can generate thousands of dollars in egress fees serving mock API responses. Disaster recovery testing, which requires restoring massive multi-terabyte backups across network boundaries, can trigger sudden, severe budget spikes. Finally, auto-scaling mechanisms directly compound the issue; when traffic spikes and triggers a 10x infrastructure scale-out, the subsequent 10x increase in data transfer volumes guarantees a proportional explosion in egress billing.
Content Delivery Networks (CDN): Proximity and Cache Economics
To mitigate exorbitant origin server egress costs and reduce page load latency—a metric that directly and measurably dictates e-commerce conversion rates—platforms universally rely on Content Delivery Networks. CDNs cache static assets at the geographical edge, serving users locally rather than routing traffic back to the central cloud region.
AWS operates Amazon CloudFront, a massively expansive global edge network deeply integrated with the AWS ecosystem. CloudFront boasts hundreds of Points of Presence (PoPs) and embedded edge locations across more than 100 cities globally, providing ultra-low latency and high throughput for international retail audiences. CloudFront utilizes a pay-as-you-go metered pricing model. Standard public pricing in North America begins at $0.085 per GB for the first 10TB, dropping to $0.060 per GB beyond 40TB. However, CloudFront costs quickly accumulate through additive feature fees; utilizing advanced routing via Lambda@Edge, generating Real-Time Logs, or triggering cache invalidation paths (charged at $0.005 per path after the first 1,000) layers significant operational costs onto the raw bandwidth bill.
To counter unpredictable metered billing, AWS offers flat-rate bundles. The CloudFront Business plan, priced at $200 per month, bundles the CDN, AWS Web Application Firewall (WAF), DDoS protection, DNS, and 50TB of data transfer. Crucially, when an organization uses CloudFront to serve data stored in Amazon S3, the origin-to-CloudFront transfer cost drops to zero, effectively eliminating internal data fetch fees and providing a massive incentive to keep the entire content delivery pipeline locked within the AWS ecosystem.
Google Cloud CDN leverages Google’s unparalleled private global fiber backbone. While it operates slightly fewer public edge locations than AWS (over 180 globally), its reliance on private transit ensures highly consistent, low-latency delivery. Cloud CDN relies on complex cache hit economics. When content is successfully served from the cache (a cache hit), the customer pays for the cache lookup and the cache data transfer out. However, on a cache miss, the customer must pay the cache lookup fee, the origin cache fill fee, and the underlying Cloud Load Balancing data processing charges. Google Cloud CDN requires the deployment of an external load balancer, introducing additional architectural components compared to CloudFront’s direct distribution model, but guaranteeing edge-level security via Google Cloud Armor.
For massive e-commerce operations pushing over 100TB per month, relying entirely on hyperscaler CDNs is often financially inefficient. Many organizations adopt a multi-CDN strategy, routing long-tail assets through specialized flat-rate CDN providers like Cloudflare or Fastly. Cloudflare offers enterprise flat-rate pricing where traffic volume does not fundamentally alter the monthly bill, providing massive predictability. Fastly offers highly competitive volume pricing ($0.018/GB for 50TB to 500TB) and zero origin egress fees under specific peering conditions. GCP actively supports this through its CDN Interconnect program; if a customer uses Fastly or Cloudflare via an approved interconnect, GCP slashes the origin egress fee from $0.08/GB down to $0.04/GB, enabling a 45% total cost reduction for massive media streaming or rich-image delivery.
Load Balancing: Unmasking the Processing Fee Trap
Load balancing is an absolutely requisite component for any scalable e-commerce infrastructure. It is responsible for intercepting global internet traffic and distributing it evenly across backend virtual machines or containers to prevent server overload. At first glance, load balancers appear highly economical, advertised at just a few cents per hour. However, load balancers contain hidden metered charges that silently inflate monthly bills, often consuming 10% to 20% of total cloud spend for mid-sized architectures.
AWS Application Load Balancer (ALB) and LCU Mathematics
The AWS Application Load Balancer (ALB) utilizes a notoriously complex billing metric known as the Load Balancer Capacity Unit (LCU). The ALB incurs a low, predictable base hourly charge of approximately $0.0225 to $0.0252 per hour just to exist. However, the usage cost is calculated via the LCU, which bills at $0.008 per LCU-hour.
The complexity arises because an LCU aggregates four entirely separate dimensions of usage:
- New Connections: 25 newly established connections per second per LCU.
- Active Connections: 3,000 active connections per minute per LCU (reduced to 1,500 if using Mutual TLS encryption).
- Processed Bytes: 1 GB of data processed per hour per LCU for standard EC2 targets.
- Rule Evaluations: 1,000 complex Layer 7 routing rules evaluated per second per LCU.
AWS charges the customer based only on the single dimension that experiences the highest usage during any given hour. For a high-traffic e-commerce site, LCU consumption can spike unpredictably. If a mobile application generates 1,000 requests per second, with clients establishing 100 new connections per second and transferring rich JSON payloads, the LCU calculation becomes a critical financial variable. In a theoretical scenario where 100 new connections per second are established, lasting three minutes each, processing 1,000 bytes per connection, and evaluating 20 custom routing rules, the load balancer will consume 6 LCUs primarily driven by active connection counts. This results in a monthly usage fee that scales exponentially during a DDoS attack or a massive legitimate traffic surge.
GCP Global Load Balancing Predictability
Google Cloud’s Global Application Load Balancer operates on a more linear and predictable financial model. It charges a base hourly rate of $0.025 per proxy instance required to handle the traffic volume. The usage cost is fundamentally based on a straightforward data processing fee of $0.008 to $0.012 per GB of data processed, alongside a secondary fee of $0.75 per million HTTP requests.
Beyond pricing predictability, GCP offers a massive architectural advantage in traffic management. GCP’s External Application Load Balancer is inherently global.
It utilizes a single anycast IP address that is advertised across Google’s worldwide network. A user in Tokyo and a user in London hit the exact same IP address, but Google’s backbone intelligently routes the traffic to the nearest healthy backend region to minimize latency. Achieving this identical global routing capability on AWS requires stringing together multiple distinct services: an ALB in each region, overlaid with Amazon Route 53 DNS policies, and fronted by AWS Global Accelerator. This AWS approach compounds architectural complexity, demands manual failover design, and significantly increases the total networking bill. For multi-region service meshes and global retail rollouts, GCP’s native global routing is a definitive technical and financial asset.
Table 2: Comparative Analysis of High-Traffic Load Balancer Cost Structures
| Load Balancer Feature | AWS Application Load Balancer (ALB) | GCP Global Application Load Balancer |
|---|---|---|
| Base Infrastructure Rate | ~$0.0225 - $0.0252 per hour | ~$0.025 per proxy instance hour |
| Data Processing Cost | Dynamically calculated via LCU metric | Flat ~$0.008 per GB processed |
| Request Billing Metric | Included within LCU calculation | ~$0.75 per million requests |
| Global Routing Capability | Requires auxiliary services (Route 53, Global Accel) | Native (Single Anycast IP address) |
| Cross-Zone Traffic Routing | Subject to standard AZ data transfer penalties | Native to Google backbone, optimized |
Database Infrastructure: Transactional Scalability versus Cost Predictability
The relational database represents the transactional heart of any digital commerce platform. It is responsible for durably storing user profiles, decrementing inventory accurately during high-concurrency checkouts, and securing payment processing pipelines. Both hyperscalers offer fully managed, highly available database services, but the operational economics of scaling these databases under the duress of e-commerce traffic dictate vastly different engineering strategies.
Amazon Aurora: The Standard vs. I/O-Optimized Dilemma
AWS’s flagship enterprise relational offering is Amazon Aurora, a highly engineered, MySQL- and PostgreSQL-compatible database featuring a proprietary distributed, shared-storage architecture. Aurora fundamentally separated the compute processing layer from the underlying storage layer, allowing for incredibly fast database cloning, rapid crash recovery, and high-performance transaction processing.
However, Aurora’s legacy pricing model (known as Aurora Standard) harbors a massive financial vulnerability for high-throughput applications. Aurora Standard charges separately for allocated storage ($0.10 per GB-month) and charges a metered fee for Input/Output (I/O) requests ($0.20 per million requests).
In the context of e-commerce, this I/O charge is highly dangerous. During a flash sale, the volume of database reads (users aggressively browsing the catalog) and writes (users adding items to carts and checking out) explodes. If the active working dataset—the products currently being browsed—exceeds the physical RAM allocated to the database instance, the Aurora engine must constantly read from the physical storage disks instead of memory. This generates millions of I/O requests per second. Under this architecture, a highly successful sales event leads to a catastrophic, unpredictable billing shock at the end of the month due to I/O metering.
Recognizing this friction, AWS introduced the Aurora I/O-Optimized configuration. This model completely eliminates all per-request read and write I/O charges. In exchange, AWS mandates higher fixed costs: the instance compute price is increased by approximately 30%, and the raw storage price is increased by 125% (rising to $0.225 per GB-month). Financial modeling provides a clear mandate: if an organization’s I/O expenditures exceed 25% of its total Aurora Standard bill, migrating the cluster to Aurora I/O-Optimized will generate immediate net savings of up to 40%. For high-throughput digital commerce platforms where traffic cannot be perfectly forecasted, the I/O-Optimized tier transforms terrifyingly unpredictable operational expenditures into stable, capacity-based billing.
Google Cloud Spanner and Cloud SQL
GCP’s response to high-end relational workloads is bifurcated into two distinct products: Google Cloud SQL for standard, monolithic MySQL/PostgreSQL workloads, and Google Cloud Spanner for applications requiring massive, unbounded global scale.
Google Cloud SQL provides highly competitive baseline pricing. Standard HDD storage drops as low as $0.09 per GB-month, while high-performance SSD storage is priced at $0.17 per GB-month. Cloud SQL integrates seamlessly with GCP’s serverless offerings like Cloud Run and Cloud Functions. However, GCP imposes steep charges for data transfer out from these databases to the public internet, making architectures that extract heavy analytical payloads directly from Cloud SQL expensive compared to alternative setups.
Google Cloud Spanner represents a fundamental paradigm shift in database engineering. Spanner is a globally distributed, relational database offering out-of-the-box horizontal scalability for both reads and writes without compromising strict transactional ACID (Atomicity, Consistency, Isolation, Durability) guarantees. Amazon Aurora struggles with horizontal write scaling, relying instead on a highly optimized, massive single-node primary write engine surrounded by multiple read replicas. Spanner, conversely, dynamically shards data across global regions, processing over 6 billion queries per second at peak loads with absolute zero-downtime scaling.
In 2024 and 2025, Google rapidly evolved Spanner into an “intelligent context hub” for AI workloads, integrating native support for vector embeddings, graph analytics, and full-text search directly into the relational engine. This allows e-commerce platforms to build real-time product recommendation engines and fraud detection algorithms using Vertex AI directly against operational transaction data without moving it to a separate data warehouse.
The severe drawback to Spanner is its architectural incompatibility. While Amazon Aurora acts as a seamless, drop-in replacement for existing MySQL or PostgreSQL applications requiring zero code changes, Spanner relies heavily on specialized gRPC interfaces and proprietary SQL dialects for inserts and updates. Migrating a legacy e-commerce application from a traditional SQL database to Spanner requires massive, foundational code refactoring. This introduces an enormous human labor cost that must be carefully weighed against the long-term infrastructure savings of infinite horizontal scaling.
Table 3: Relational Database Cost and Architecture Matrix
| Database Platform | Architectural Paradigm | Primary Pricing Model / Expense Driver | Optimal E-commerce Use Case |
|---|---|---|---|
| Amazon Aurora (Standard) | Single-primary, distributed storage | Storage + Metered I/O transaction fees | Low-traffic or highly cached catalogs |
| Amazon Aurora (I/O-Opt) | Single-primary, distributed storage | Premium Storage + Premium Compute (Zero I/O) | High-volume, unpredictable holiday traffic |
| Google Cloud SQL | Managed MySQL/Postgres instances | Provisioned Storage + Compute capacity | Standard, predictable monolithic applications |
| Google Cloud Spanner | Globally distributed, horizontally scalable | Node-based compute + Regional Storage | Massive global scale; mandates code rewrite |
In-Memory Caching: The Usable Keyspace Deception
To alleviate the immense strain on primary relational databases and provide the sub-millisecond response times required for rendering complex product catalogs and managing active user sessions, e-commerce platforms rely heavily on in-memory datastores, primarily Redis. AWS offers Amazon ElastiCache, while GCP provides Memorystore. A superficial comparison of hourly instance node prices between these two services presents a fundamentally inaccurate picture of true caching costs at scale.
The greatest hidden financial driver in Amazon ElastiCache is the “usable keyspace tax.” AWS strictly mandates that a significant portion of the total provisioned node memory be reserved for background operational tasks, such as automated backups, snapshotting, and cluster replication processes. By default, AWS requires a minimum 25% memory reservation. On smaller node types (such as the burstable t-class instances), this required reservation increases to 30%, and for micro nodes, it reaches an astonishing 50%.
Consequently, if an organization purchases an ElastiCache cache.r7g.xlarge instance—which is advertised with 26.32 GiB of raw memory—they will only have access to approximately 19.7 GiB of actual usable keyspace for caching live product data. If an engineering team calculates their cache cluster size based on raw hardware specifications rather than this restricted usable keyspace, they face a critical dilemma under high load: they must endure out-of-memory errors that force brutal data eviction (which immediately crashes the primary database with read-through queries), or they must aggressively increase their ElastiCache budget by provisioning larger nodes or adding more shards to the cluster. AWS’s architectural requirement for High Availability further exacerbates this financial pain, demanding two or more replicas spread across different Availability Zones, essentially tripling the provisioned memory footprint required to store a single dataset securely in production.
Adding further financial pressure, AWS enforces “Extended Support” premiums for legacy Redis versions. As older versions of ElastiCache for Redis OSS reach end-of-support (such as version 5 reaching end-of-support in January 2026), customers who cannot immediately upgrade their application code are subjected to punitive pricing.
For the first two years of Extended Support, the hourly node charge incurs an 80% premium. By the third year, this premium explodes to 160%.
Google Cloud Memorystore handles memory provisioning and pricing with a fundamentally different, capacity-tiered approach. Memorystore offers a Basic Tier (a standalone node providing an ephemeral cache suitable only for development) and a Standard Tier (providing high availability with automatically enabled cross-zone replication and automatic failover). Pricing is determined by capacity tiers ranging from M1 (1 to 4 GiB) up to M5 (greater than 100 GiB).
For a comparable 26GB instance (which falls into the Memorystore M3 capacity tier of 11 to 35 GiB), Memorystore charges a variable per-GB/hour rate. A Standard Tier M3 instance costs approximately $0.046 per GB/hour. Because Memorystore is fully managed by Google, it handles the underlying infrastructure overhead without aggressively restricting the advertised capacity to the same extreme degree as ElastiCache’s strict reservation enforcement. Furthermore, GCP allows 1-year and 3-year Committed Use Discounts specifically tailored for Memorystore, reducing costs by 20% to 40% respectively, providing a highly predictable cost structure for massive session state management.
Serverless Execution and Free Tier Economics
As e-commerce architectures transition away from monolithic virtual machines toward event-driven microservices, serverless compute functions play a vital role in executing lightweight tasks, such as triggering an email receipt upon successful payment or resizing a user-uploaded image.
Historically, AWS Lambda dominated this space with an incredibly generous “Always Free” tier. However, on July 15, 2025, AWS executed a massive overhaul of its Free Tier structure for new accounts. The legacy 12-month free trial model was replaced with a credit-based “Free Plan.” New accounts receive a block of credits (e.g., $100+) valid for a strictly limited 6-month period to explore the ecosystem. Once the 6-month period expires—or the credits are exhausted—the account is subject to closure unless explicitly upgraded to a Paid Plan, and data is wiped after a 90-day grace period. While over 30 “Always Free” services remain, this shift forces startups to adopt rigorous FinOps practices immediately upon inception rather than coasting on free infrastructure for a year.
Google Cloud Platform maintains highly competitive free allowances for its serverless environments. Google Cloud Run (for serverless containers) and Cloud Run functions (for event-driven code) offer a permanent Free Tier that includes 2 million requests per month, alongside 360,000 GB-seconds of memory and 180,000 vCPU-seconds of compute time. For an emerging e-commerce brand or a lean startup, GCP’s ability to handle 2 million asynchronous serverless invocations monthly at absolute zero cost represents a massive financial incentive to build purely cloud-native architectures from day one.
FinOps Integration and Real-World TCO Migrations
The theoretical cost advantages of either hyperscaler platform are frequently unrealized without the aggressive integration of Cloud Financial Management (FinOps) disciplines. A static, unoptimized “lift and shift” migration from on-premises hardware directly to either AWS or GCP will invariably result in catastrophic budget overruns. Real-world case studies illustrate the absolute necessity of systematic, architectural optimization.
GCP Migration: The ShipEasy Case Study
ShipEasy, a rapidly scaling logistics and e-commerce marketplace, experienced runaway cloud costs due to unpredictable traffic spikes and the rigid infrastructure provisioning required by their legacy AWS environment. Internal, rudimentary attempts to optimize AWS costs by simply downgrading EC2 server sizes to cheaper tiers resulted in degraded user experiences, slower response times, and system downtime.
By partnering with cloud architects to execute a strategic redesign and migrating the entire application stack to Google Cloud Platform, ShipEasy achieved a massive 45% reduction in overall cloud spend within the first quarter. These financial savings were not achieved through direct, unit-price arbitrage—simply swapping an AWS server for a slightly cheaper GCP server. Instead, savings were driven by profound architectural alignment with GCP’s core strengths:
- Right-Sizing Compute Engine VMs: Analyzing granular usage patterns to optimize Compute Engine virtual machines, cutting wasted capacity without compromising peak performance.
- Modernized Data Layer: Shifting legacy databases to GCP Cloud SQL, leveraging its built-in auto-scaling and high availability to remove the manual, cumbersome provisioning constraints of their previous AWS RDS setup.
- Proactive Cost Control Visibility: Integrating Google’s Cloud Operations Suite (comprising logging, metrics, and alerting) to provide the visibility necessary for proactive budget management.
The ShipEasy migration emphatically highlights that GCP’s primary financial advantage stems from its inherent elasticity. The ability of the infrastructure to scale up seamlessly during logistics peaks and scale down completely during idle hours—without the friction of complex AWS provisioning rules—ultimately drove the 45% TCO reduction and freed up capital for product innovation.
AWS Native Remediation and Optimization
Conversely, organizations deeply entrenched in AWS do not necessarily need to execute a risky multi-cloud migration to achieve drastic savings; they can achieve similar TCO reductions by rigorously auditing their existing environments. A separate high-traffic e-commerce platform successfully executed a 75% cloud budget reduction entirely within AWS through a highly structured, four-pillar remediation strategy:
- Resource Orphan Mitigation: The organization recovered $4,000 monthly merely by utilizing scripts to identify and delete unattached Elastic Block Store (EBS) volumes that were left behind by terminated EC2 instances.
- Fleet Right-Sizing: They generated $18,000 in monthly savings by actively aligning EC2 instance families with real-time CPU and memory metrics, moving away from over-provisioned legacy instances.
- Storage Tier Modernization: They reduced block storage spend by $3,000 by migrating from legacy gp2 volumes to modern gp3 volumes, immediately securing a 40% per gigabyte cost reduction while decoupling IOPS provisioning.
- Aggressive Rate Optimization: They locked in $20,000 in monthly savings by forecasting their baseline compute floor and intelligently applying AWS Compute Savings Plans and Reserved Instances to their steady-state workloads.
This dichotomy between the two case studies demonstrates a crucial, third-order insight: AWS provides unparalleled depth for financial optimization, but it absolutely requires an active, highly sophisticated FinOps engineering culture to prevent massive waste (e.g., manually hunting orphaned EBS volumes or tracking the deprecation of storage types). GCP’s automated mechanisms (like Sustained Use Discounts) and Custom Machine Types act as an inherent safety net, automatically capturing efficiencies that AWS requires deliberate human intervention to unlock.
Strategic Conclusions and 2026 Optimization Directives
The determination of the “most cost-effective” cloud hosting environment for a high-traffic e-commerce platform cannot be reduced to a binary evaluation of unit pricing. The true cost of the cloud is an ecosystem equation derived from the intersection of baseline compute rates, the topology of the global network, the automation level of discounting mechanisms, and the human operational labor required to maintain the architecture securely.
The analytical evidence points to distinct strategic recommendations based on organizational maturity, architectural philosophy, and specific workload profiles:
- The Strategic Mandate for Google Cloud Platform (GCP): GCP is demonstrably more cost-effective for organizations prioritizing cloud-native architectures, heavy containerization (via Kubernetes), and rapid software innovation without the desire to build heavy, dedicated FinOps administrative departments. The inherent global nature of GCP’s VPCs radically simplifies multi-region deployments, functionally eliminating the punitive “HA tax” associated with AWS cross-AZ traffic routing. Automatic Sustained Use Discounts (SUDs) protect retail organizations from cost overruns caused by the volatile, unpredictable nature of e-commerce traffic. For startups leveraging the generous 2 million request Free Tier for serverless execution, or mid-market retailers building greenfield applications, GCP offers a measurably lower total cost of ownership by minimizing DevOps overhead and integrating deeply with world-class, serverless data analytics like BigQuery.
- The Strategic Mandate for Amazon Web Services (AWS): AWS remains the premier, undisputed choice for massive, established e-commerce enterprises running highly complex, heterogeneous legacy workloads. Its primary architectural advantage is absolute, granular control over every networking packet and compute cycle. When managed by a dedicated, mature FinOps team capable of navigating the complexity, AWS’s ecosystem of Spot Instances, Graviton4 custom ARM silicon (yielding 120% better price-performance), and multi-year Compute Savings Plans can drive the absolute unit cost of compute lower than any competitor.
Furthermore, the transition of Amazon Aurora to the I/O-Optimized pricing model successfully neutralizes its biggest historical financial flaw, making it a highly predictable, enterprise-grade transactional backend capable of sustaining the most aggressive Black Friday retail events without triggering billing shocks.
Ultimately, as the industry moves deep into 2026, the cloud pricing war is shifting away from a race to the bottom on raw compute and storage, evolving into a battle over premium architectural integrations and the avoidance of hidden network taxes. Success in high-traffic e-commerce hosting relies fundamentally on designing the application architecture to fit the specific billing contours of the chosen provider. An application optimized for AWS will hemorrhage cash if blindly lifted into GCP, and vice versa. True cost-effectiveness is achieved through continuous architectural alignment, the aggressive integration of native managed services, and uncompromising, relentless visibility into data egress paths.


